8. Local LLMs in Practice¶
Freedom is something that dies unless it’s used.
—Hunter S. Thompson
8.1. Introduction¶
Running Open Source LLMs locally versus depending on proprietary cloud-based models represents more than just a technical choice - it’s a fundamental re-imagining of how we interact with AI technology, putting control back in the hands of users.
Privacy concerns are a key driver for running LLMs locally. Individual users may want to process personal documents, photos, emails, and chat messages without sharing sensitive data with third parties. For enterprise use cases, organizations handling medical records must comply with HIPAA regulations that require data to remain on-premise. Similarly, businesses processing confidential documents and intellectual property, as well as organizations subject to GDPR and other privacy regulations, need to maintain strict control over their data processing pipeline.
Cost considerations are another key driver. Organizations and individual consumers can better control expenses by matching model capabilities to their specific needs rather than paying for multiple cloud API subscriptions. For organizations with high-volume applications, this customization and control over costs becomes especially valuable compared to the often prohibitive per-request pricing of cloud solutions. For consumers, running multiple open source models locally eliminates the need to maintain separate subscriptions to access different model capabilities.
Applications with stringent latency requirements form another important category. Real-time systems where network delays would be unacceptable, edge computing scenarios demanding quick responses, and interactive applications requiring sub-second performance all benefit from local deployment. This extends to embedded systems in IoT devices where cloud connectivity might be unreliable or impractical. Further, the emergence of Small Language Models (SLMs) has made edge deployment increasingly viable, enabling sophisticated language capabilities on resource-constrained devices like smartphones, tablets and IoT sensors.
Running open source models locally also enables fine-grained optimization of resource usage and model characteristics based on target use case. Organizations and researchers can perform specialized domain adaptation through model modifications, experiment with different architectures and parameters, and integrate models with proprietary systems and workflows. This flexibility is particularly valuable for developing novel applications that require direct model access and manipulation.
However, local deployment introduces its own set of challenges and considerations. In this Chapter, we explore the landscape of local LLM deployment focused on Open Source models and tools. When choosing a local open source model, organizations must carefully evaluate several interconnected factors, from task suitability and performance requirements to resource constraints and licensing.
We also cover key tools enabling local model serving and inference, including open source solutions such as LLama.cpp, Llamafile, and Ollama, along with user-friendly frontend interfaces that make local LLM usage more accessible. We conclude with a detailed case study, analyzing how different quantization approaches impact model performance in resource-constrained environments. This analysis reveals the critical tradeoffs between model size, inference speed, and output quality that practitioners must navigate.
8.2. Choosing your Model¶
The landscape of open source LLMs is rapidly evolving, with new models emerging by the day. While proprietary LLMs have garnered significant attention, open source LLMs are gaining traction due to their flexibility, customization options, and cost-effectiveness.
It is important to observe long-term strategic considerations when choosing a model. These entails prioritization dimensions that may enable competitive advantage in the long-term, including:
Managed Services Support: You may start experimenting locally with LLMs but eventually you will need to deployment options: either host models yourself or consider managed services. Cloud providers like AWS Bedrock, SambaNova and Together.ai can simplify deployment and management but model family support varies along with varying SLAs for model availability, support and model serving [Analysis, 2024]. One should evaluate the availability of managed services for your target model family.
Vendor Long-Term Viability: Consider vendor’s long-term strategy and transparency around future development. Evaluate factors like funding, market position, and development velocity to assess whether the vendor will remain a reliable partner. Further, transparency around long-term strategy and roadmap is a critical consideration when choosing a model vendor partner.
Single-Provider Lock-in: Users and organizations should avoid the risk of lock-in by remaining flexible with your choice of LLM providers. Today’s winning models are not guaranteed to be the same in the future.
Time-to-market and Customization: As the same models are available to everyone, base capabilities are becoming commoditized. As a consequence, competitive advantage comes from the application layer. Hence, the ability to iterate fast while customizing to your specific domain becomes a critical strategic consideration when choosing a model.
Data Competitive Edge: As the cost of (pre-trained) general intelligence decays rapidly, proprietary data becomes competitive advantage. Hence, the ability to add unique, custom, domain-specific datasets to base models is a critical consideration that will separate winners from losers.
In this section, we aim to provide a comprehensive set of considerations to selecting the right open-source LLM for your specific needs, emphasizing the importance of aligning the LLM’s capabilities with the intended task and considering resources constraints.
8.2.1. Task Suitability¶
When evaluating an open source LLM, task suitability is a critical first consideration. A model that performs well on general benchmarks may struggle with specific domain tasks. Understanding the intended use case helps narrow down model options based on their demonstrated strengths.
Task Categories
When determining which LLM task to prioritize, carefully consider your specific use case and end-user needs. Different applications require distinct model capabilities and optimizations. Common LLM Task Categories include:
Text Summarization: Condensing documents into concise summaries that capture key information.
Question Answering: Providing accurate responses by extracting relevant information from knowledge bases.
Text Generation: Creating high-quality content across formats, from documentation to creative writing.
Code Generation: Writing clean, documented code in multiple programming languages.
Language Translation: Converting text between languages while preserving meaning and nuance.
Dialogue Systems: Enabling natural conversations for customer support and interactive learning.
Text Classification: Categorizing and labeling text data for sentiment analysis, topic modeling, and content moderation.
Named Entity Recognition: Identifying and extracting specific entities from text, such as people, organizations, and locations.
Fig. 8.1 shows the number models per task category available at Hugging Face as of December 22, 2024 [HuggingFace, 2024t]. Text generation is by far the most popular task category.
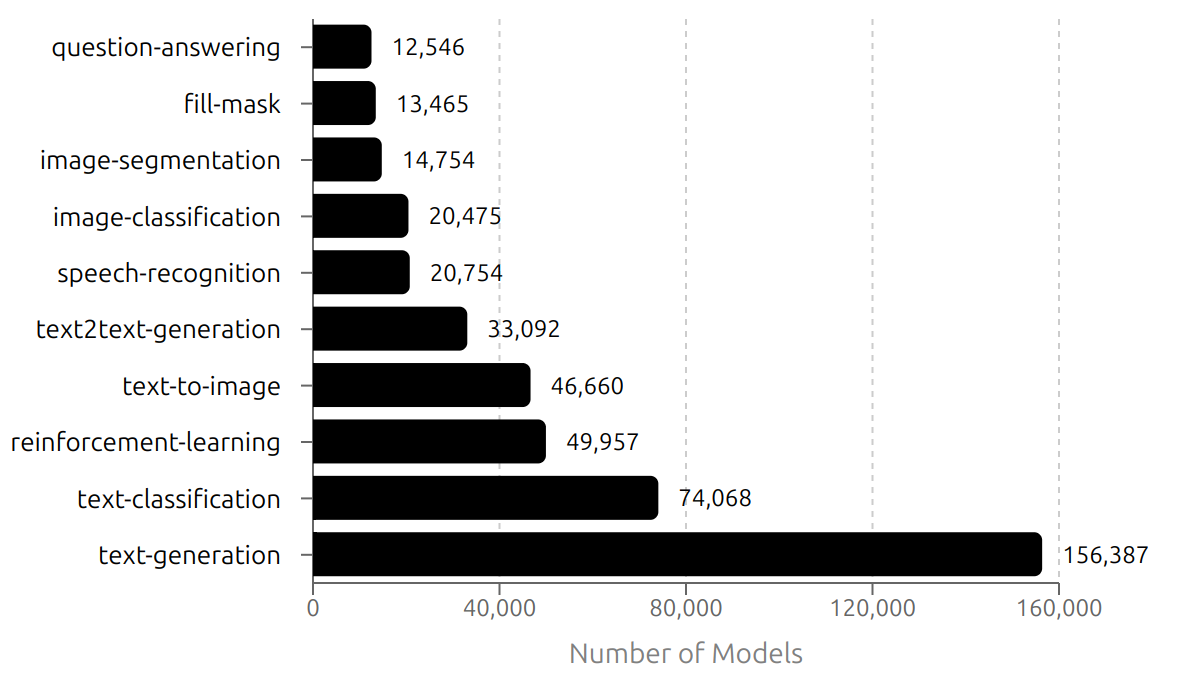
Fig. 8.1 Number of models per task category from Hugging Face as of December 22, 2024 [HuggingFace, 2024t].¶
Model Types
Open source LLMs can be broadly categorized into three main types as far as they level of customization is concerned, each with distinct characteristics and use cases (see Fig. 8.2):
Base Models: These foundation models provide broad language understanding capabilities but typically require additional fine-tuning to excel at specific tasks. They serve as versatile starting points for customization. Examples: meta-llama/Llama-2-70b, Qwen/Qwen2.5-72B
Instruction-Tuned Models: Enhanced through fine-tuning on instruction-following datasets, these models excel at interpreting and executing explicit prompts and commands. They bridge the gap between general language capabilities and practical task execution. Chat models are a good example of this category. Examples: meta-llama/Llama-2-70b-chat-hf (Chat), Qwen/Qwen2.5-72B-Instruct
Domain-Adapted Models: Specialized for particular fields through targeted fine-tuning and/or preference-alignment on domain-specific data. Examples: Med-PaLM 2 for healthcare, BloombergGPT for finance.

Fig. 8.2 Model Types.¶
The Llama 2 model family [Touvron et al., 2023] illustrates these distinctions well. The base Llama 2, trained on 2 trillion tokens of public data, demonstrates general-purpose capabilities across text generation and translation tasks. Its chat-optimized instruction-tuned variant, Llama 2-Chat, underwent additional fine-tuning on over 1 million human-annotated conversational examples, making it particularly adept at natural dialogue.
Benchmark results [Meta AI, 2024c] in Table 8.1 highlight the impact of model specialization. On the TruthfulQA [Lin et al., 2022] and Toxigen [Alnajjar and others, 2024] benchmarks measuring truthful and informative responses. We observe that the chat-optimized variants show substantially improved truthfulness. Similarly, on the ToxiGen benchmark measuring toxic content generation, Llama 2-Chat models demonstrate near-zero toxicity compared to base models’ 21-26% rates.
Model |
Size |
TruthfulQA |
Toxigen |
|---|---|---|---|
Llama 2 |
7B |
33.29 |
21.25 |
Llama 2 |
13B |
41.86 |
26.10 |
Llama 2 |
70B |
50.18 |
24.60 |
Llama-2-Chat |
7B |
57.04 |
0.00 |
Llama-2-Chat |
13B |
62.18 |
0.00 |
Llama-2-Chat |
70B |
64.14 |
0.01 |
While Llama family of models exhibits strong performance across general knowledge, instruction following, and specialized domains, purpose-built models may still outperform it in highly specific applications. Qwen/Qwen2.5-Coder-32B-Instruct [Hui et al., 2024] is an example of a purpose-built model that demonstrates significant performance on the specific task of code generation.
Model Features
Model features can either enable or limit the feasibility of specific use cases. Understanding features of your candidate models is crucial for determining whether a model is suitable for your application. For example:
Context Length: The model’s ability to process longer text sequences directly impacts task suitability. A legal contract analysis systems requiring the model to reason about a 5000-page document would be impractical with a model limited to 2,048 tokens, while models supporting 2M tokens could handle this task effectively without the need for other techniques e.g. context chunking.
Output Control: Some tasks require precise, factual and structured outputs while others allow more creative, unstructured generation. Models vary in their output reliability. Grammar constraints and other control mechanisms may be needed to ensure reliable outputs. See Chapter Structured Output for more details.
Caching: Models that support caching can speed up inference at lower costs. This becomes particularly important for applications requiring cost-effective real-time responses.
Multi-modal Capabilities: Some applications fundamentally require multi-modal processing. A medical diagnosis assistant analyzing both patient records and X-ray images would be impossible to implement with a text-only model, necessitating a multi-modal model that can process both text and images coherently.
Output Token Length: The model’s capacity to generate longer responses affects its suitability for content generation tasks. A model excelling at concise responses may struggle with long-form content creation like technical documentation or detailed analysis reports.
8.2.2. Performance & Cost¶
General benchmarks are useful for comparing models across different standard tasks. Open Source models are becoming more competitive with proprietary models with LLama, Qwen, DeepSeek and Mistral model families being some of the most powerful open source models available today.
Qwen model family [Qwen et al., 2024] emerged in 2024 as a model family achieving competitive performance with relatively smaller parameter counts compared to its competitors. The flagship Qwen2.5-72B-Instruct model demonstrates performance comparable to the much larger Llama-3-405B-Instruct while being about 5 times smaller. The models excel in specialized tasks like mathematics and coding, handle structured data effectively, and offer enhanced support for tool use and long-text generation as shown in Fig. 8.3.
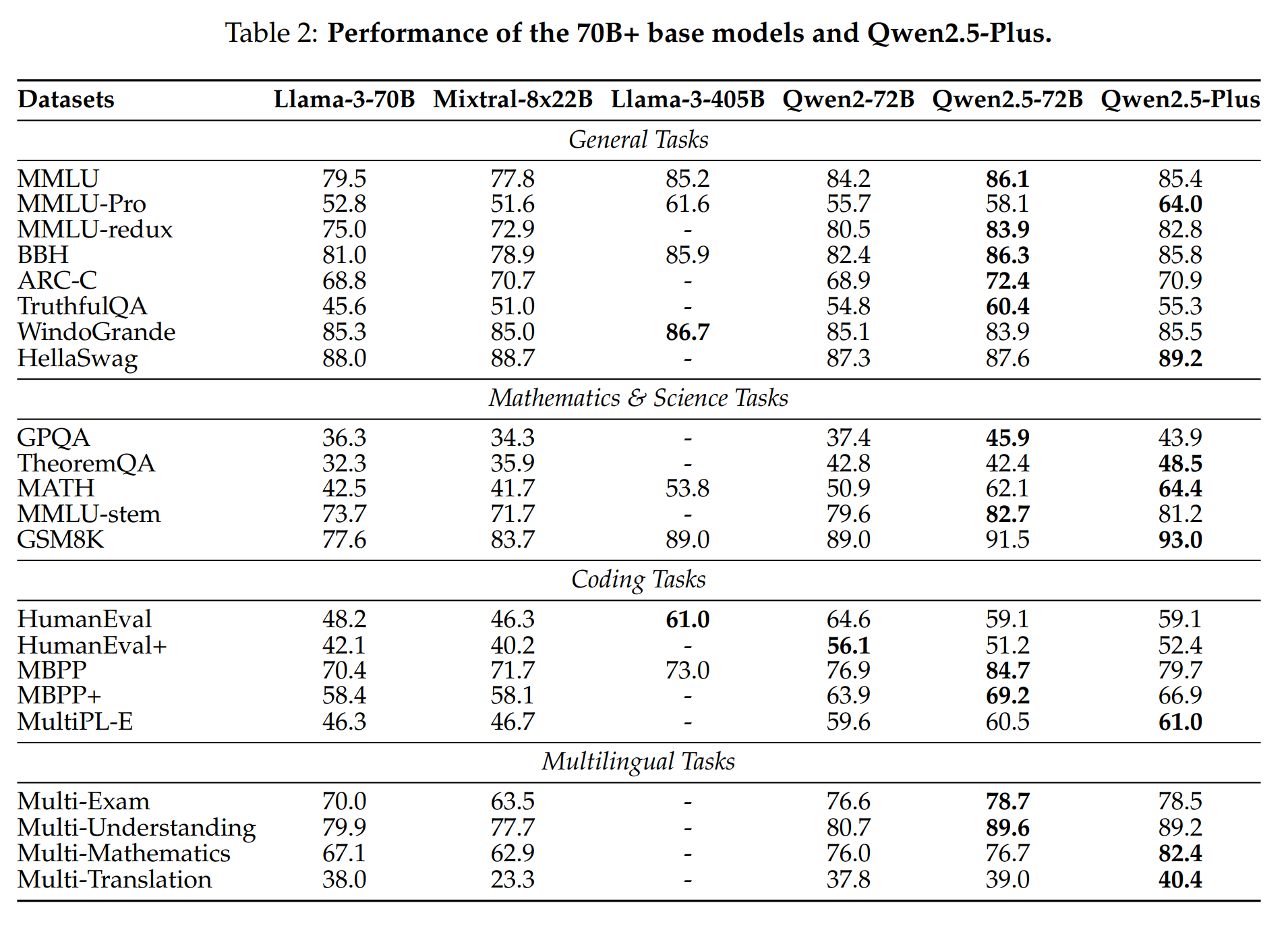
Fig. 8.3 Qwen Performance.¶
Fig. 8.4 shows a comparison including reference proprietary models such as GPT-40, Gemini 1.5 Pro and Claude 3.5 Sonnet. Leading models vary per domain but all top ranking models are proprietary. However, open source models do show competitive performance with Qwen and LLama models leading the pack, overall.
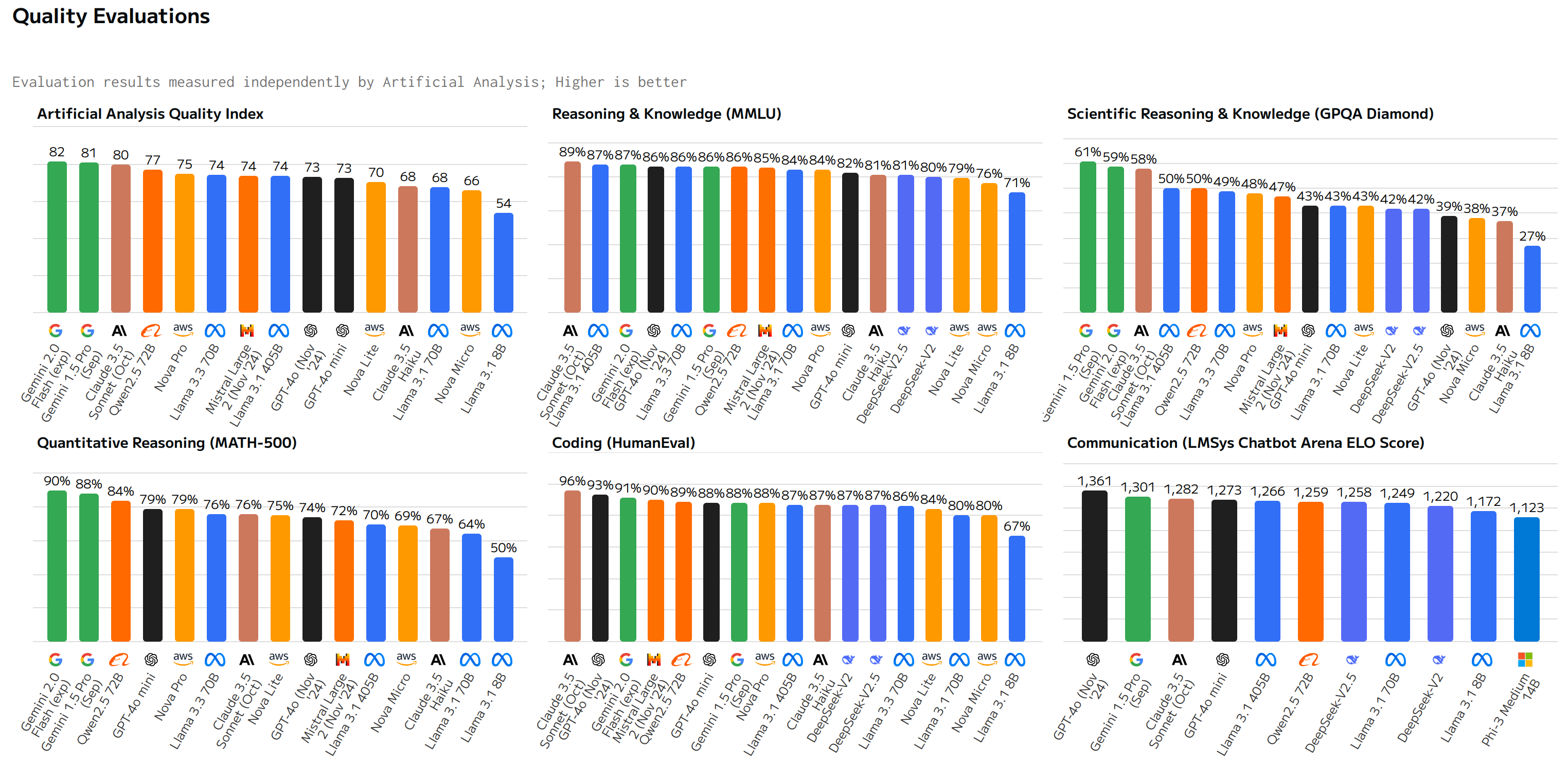
Fig. 8.4 Performance Comparison including proprietary models.¶
Also from China, DeepSeek-V3 [DeepSeek, 2024] represents a major breakthrough in open source language models, emerging as arguably the most capable open source large language model available as of the end of 2024. With 671 billion parameters and 37 billion active MoE (Mixture of Experts) parameters, it achieves performance on par with leading proprietary models like Claude 3.5 Sonnet and GPT 4o as shown in Fig. 8.5. The model demonstrates impressive cost efficiency metrics (see Fig. 8.6), processing input tokens at \(0.27 per million and output tokens at \)1.1 per million, while maintaining a generation speed of 60 tokens per second (3x faster than DeepSeek-V2).
What makes DeepSeek-V3 particularly remarkable is that these capabilities were achieved with a relatively modest training budget of just $5.5 million, used to train on 14.8 trillion tokens. This efficiency in training demonstrates the potential for open source models to compete with proprietary alternatives at a fraction of the cost. The model’s release marks a significant milestone in the democratization of advanced AI capabilities, challenging the dominance of proprietary models within big tech. One should be cautious though as the model has not yet been battle-tested in the wild but this is an exciting development demonstrating the potential of open source models to compete with proprietary alternatives.
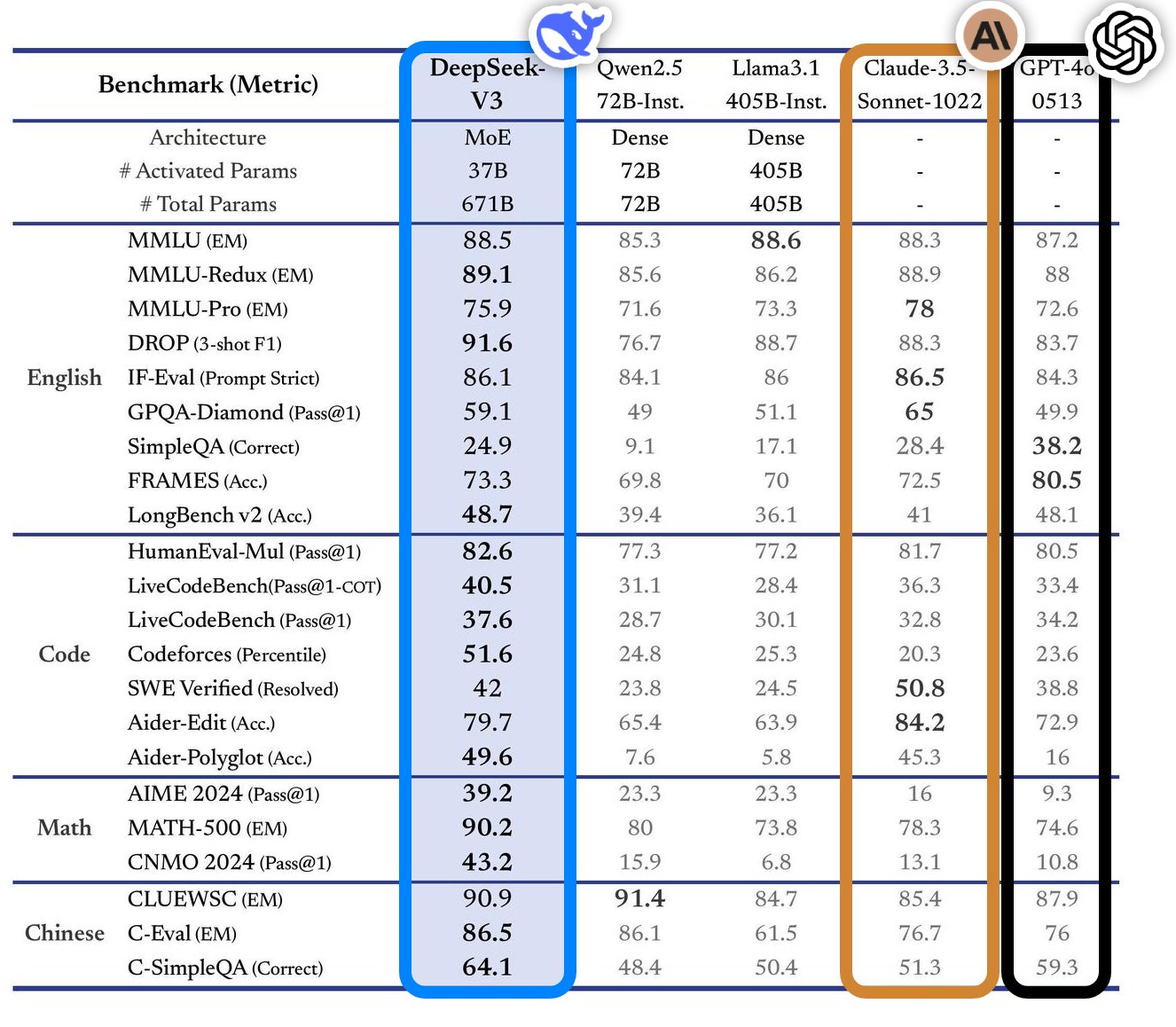
Fig. 8.5 DeepSeek-V3 Performance Comparison¶
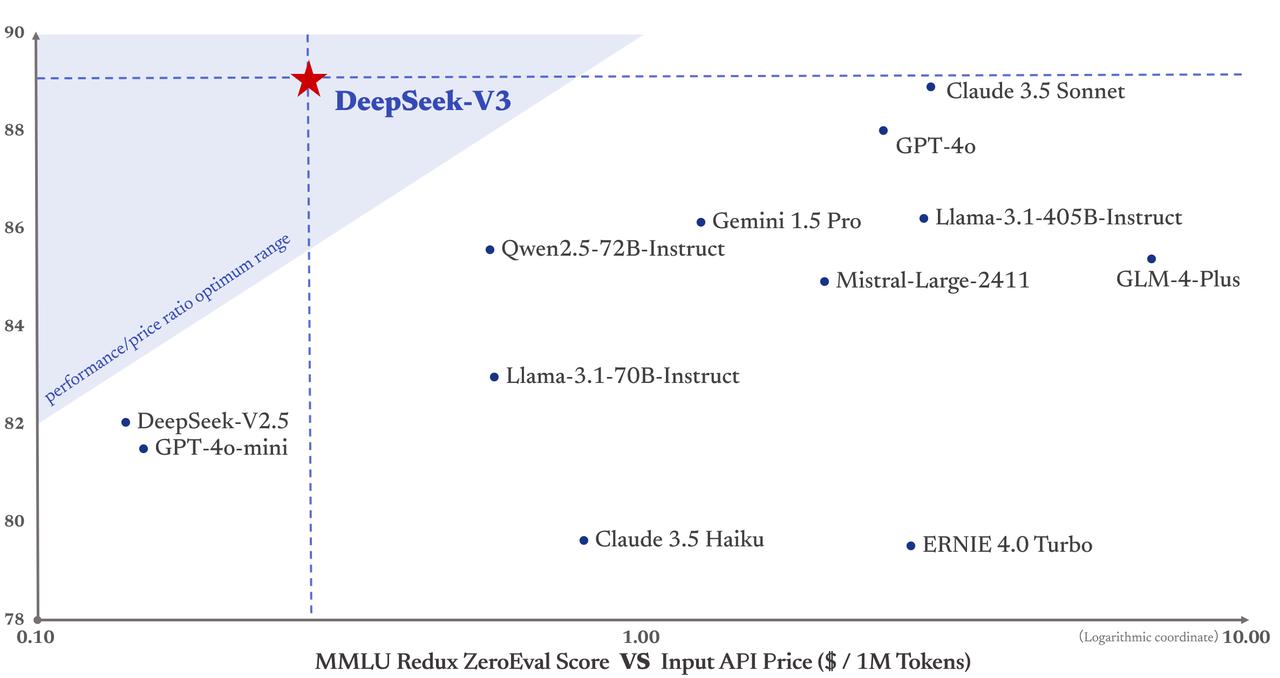
Fig. 8.6 DeepSeek-V3 Cost Benefit Analysis¶
While standard benchmarks provide valuable initial insights, they should be interpreted cautiously since models can be specifically optimized for these popular tests without necessarily performing well in target use cases. This necessitates developing custom evaluation frameworks with real-world validation - creating test datasets representing actual usage scenarios, defining metrics aligned with business objectives, and establishing clear baselines and improvement targets. Only through such rigorous testing can practitioners truly understand how well a model will perform in their specific context.
In that way, after identifying candidate models, it’s essential to rigorously evaluate their capabilities against unique use case requirements and constraints, as models that excel in standardized tests may struggle with the nuanced demands of real-world applications. Chapter The Evals Gap explores this critical challenge in detail, providing frameworks and best practices for comprehensive model evaluation.
Model quality performance should not be evaluated in isolation. It is important to also consider the cost of running the model once it’s deployed as well as its computational performance. This depends on the model size, hardware, and the platform used (self-hosted vs. managed services). Key metrics include:
Cost-Related:
Cost Per Output Token (CPOT): This metric measures the cost of text generation.
Cost Per Input Token (CPIT): This metric measures the cost for input prompt processing.
Total Cost of Ownership (TCO): Consider the full lifecycle cost, including development, deployment, maintenance, infrastructure, and ongoing iteration.
Time-Related:
Time Per Output Token (TPOT): This metric measures the speed of text generation and is crucial for user experience, especially in interactive applications.
Time to First Token (TTFT): Essential for streaming applications like chatbots, as it measures how quickly the model begins generating a response.
Latency: Time to first token of tokens received, in seconds, after API request sent. For models which do not support streaming, this represents time to receive the completion.
Fig. 8.7 shows a comparison of quality now with the added dimension of cost. Quality is measured as an average of scores from MMLU, GPQA, Math & HumanEval benchmarks [Analysis, 2024]. Price is a blend of Cost Per Input Token plus Input & Cost Per Output Token (3:1 ratio). Reported numbers represent median across cloud providers [Analysis, 2024] supporting these models.
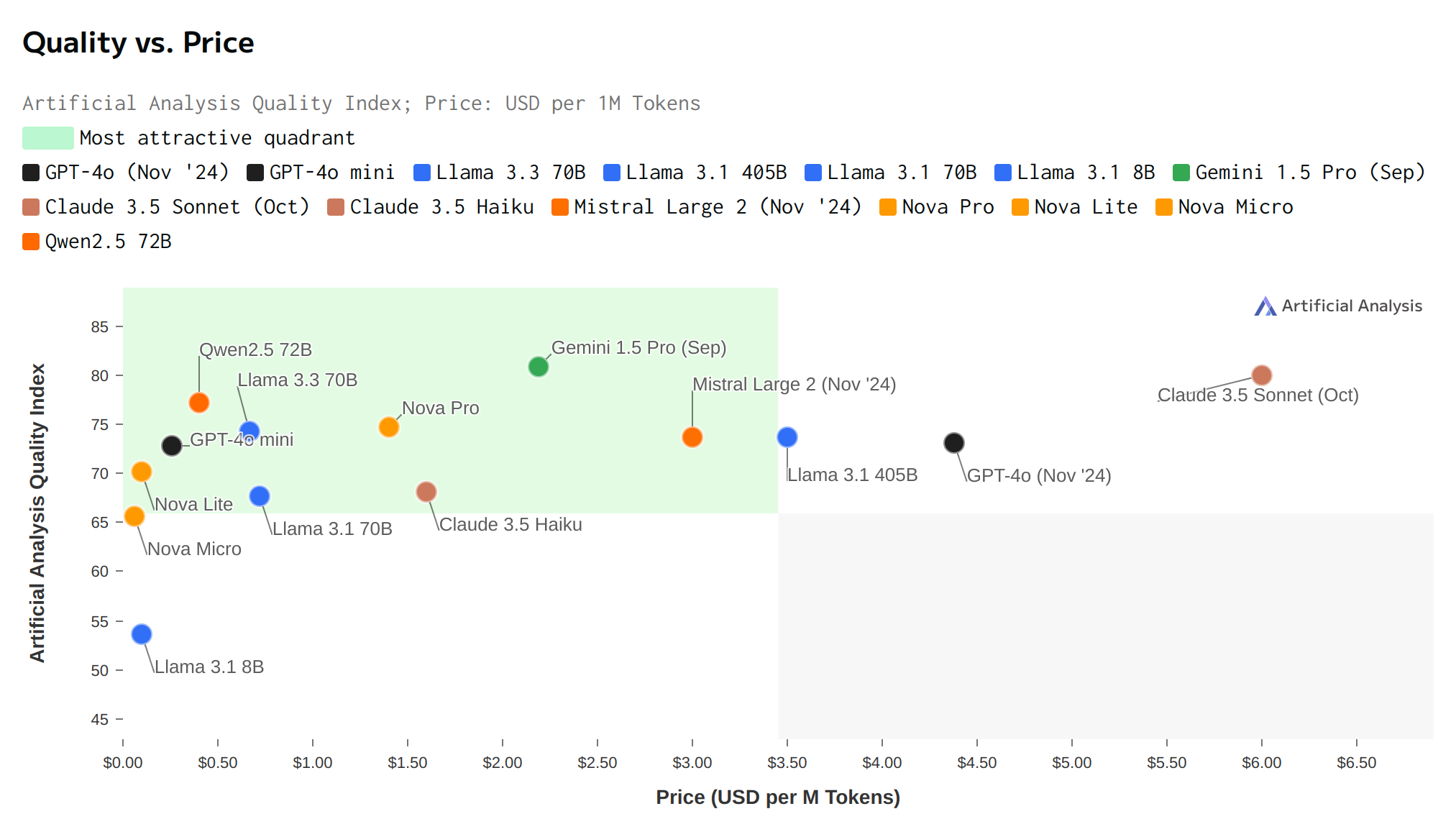
Fig. 8.7 Performance Comparison including proprietary models.¶
We observe Qwen2.5 72B and Llama 3.3 70B offer the best value among Open Source models, providing high quality at a relatively affordable price comparable to GPT-4o mini, for instance. Meanwhile Nova Lite, Nova Micro, and Llama 3.1 8B demonstrate to be budget-friendly options catering to use cases where cost is a significant factor and some compromise on quality is acceptable.
From Fig. 8.8 we have evidence that output prices are higher than input prices. This reflects the greater computational resources typically required at inference time for output compared to processing input text (e.g. tokenization, encoding). We also observe a quite significant variation in pricing across different models. Prices range from a few cents per 1M tokens (e.g., Gemini 2.0 Flash, Nova Micro, Nova Lite) to several dollars per 1M tokens (e.g., Claude 3.5 Sonnet, GPT-4o). Mistral large 2 is the most expensive model at \(2/\)6 per 1M input/output tokens while Nova Micro family is the cheapest among Open Source options.
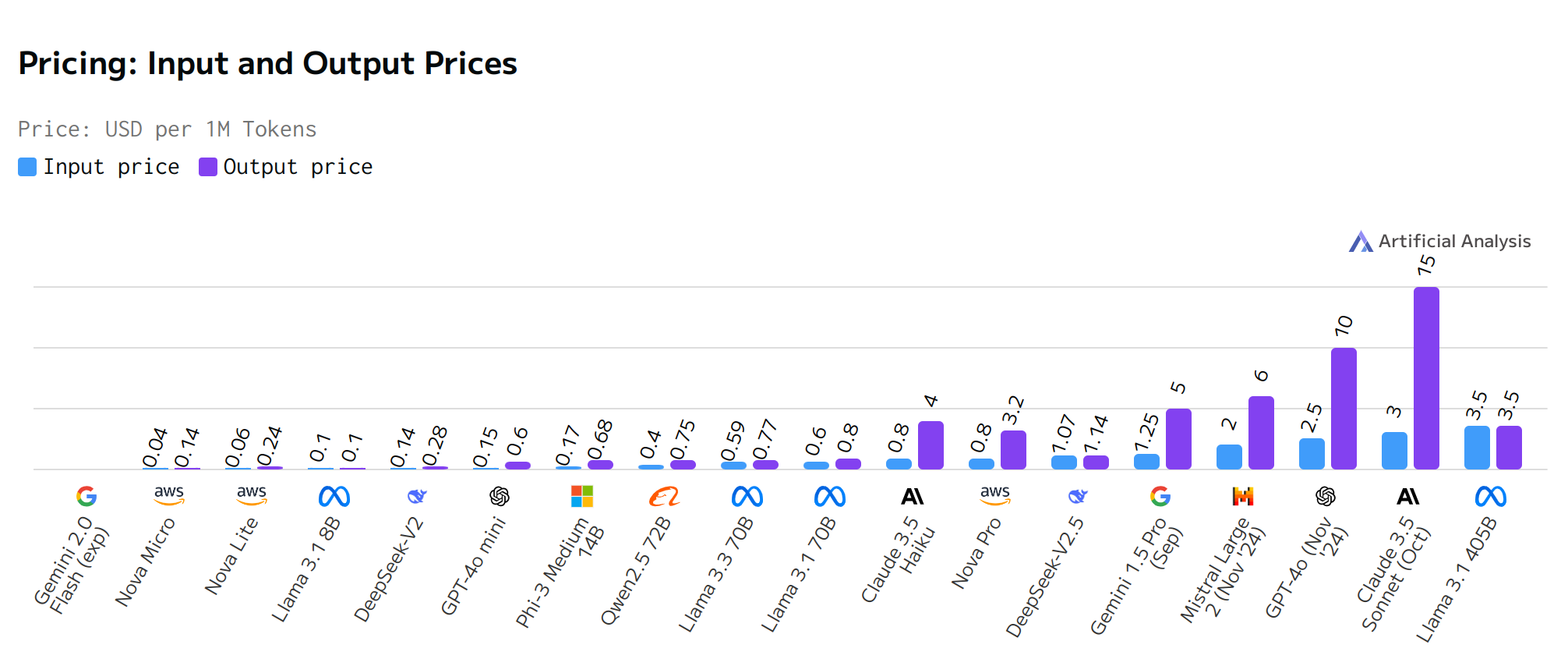
Fig. 8.8 Input and Output Prices Comparison.¶
Latency figures in Fig. 8.9 put GPT-4o (Nov ‘24) as the best performing model but Llama, Nova Micro, Phi and Mistral model families all have options with latency of half a second or better beating Gemini and Claude models considered as well as GPT-4o mini.
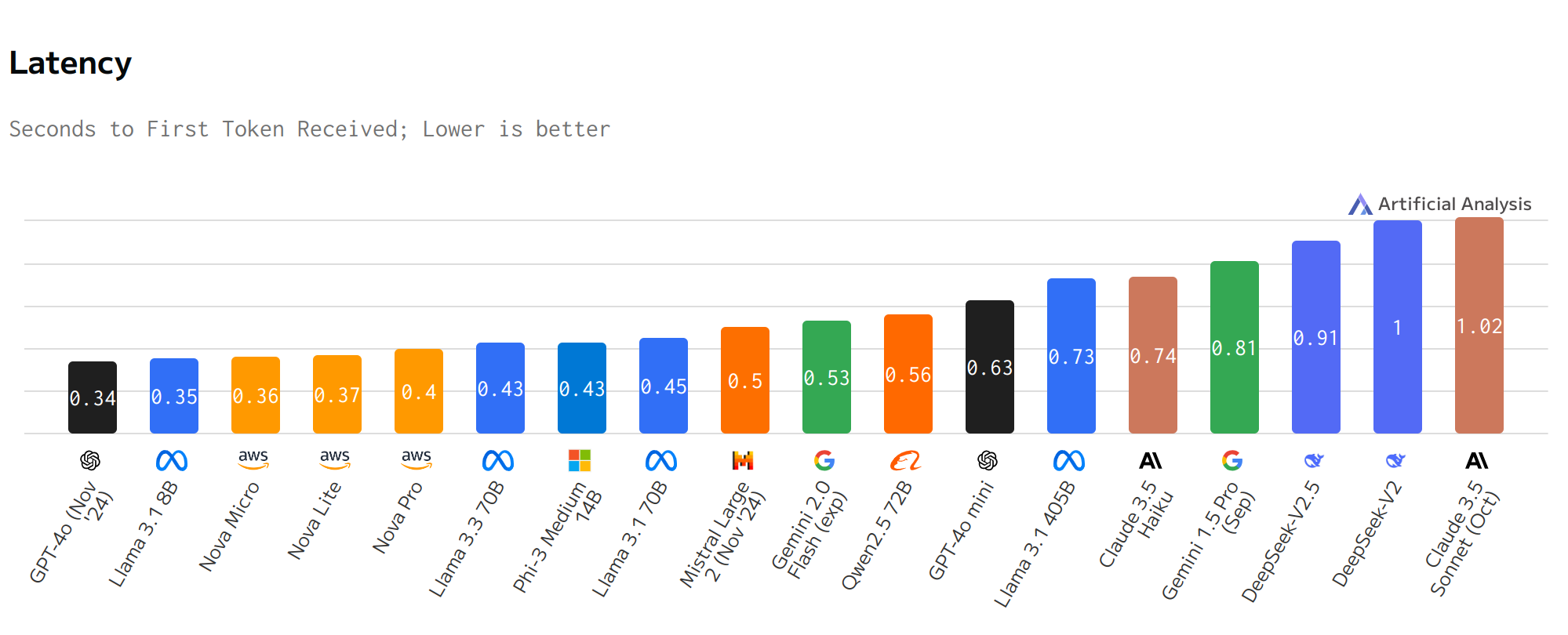
Fig. 8.9 Latency Comparison.¶
This analysis provides a framework for evaluating key performance considerations when selecting an LLM. While the specific figures for cost, latency, and quality change frequently (often daily) as providers update their offerings and pricing, the fundamental tradeoffs remain relevant. When evaluating model suitability for a specific use case, practitioners should carefully consider:
The balance between quality requirements and cost constraints
Latency requirements for the intended application
Total cost of ownership including both input and output token costs
Whether streaming capabilities are needed (TTFT becomes more critical)
Infrastructure and deployment costs
Regular re-evaluation of these metrics is recommended as the landscape evolves rapidly. What represents the optimal choice today may change as new models are released and existing ones are updated.
8.2.3. Licensing¶
When evaluating open-source LLMs, it’s important to consider licensing and data usage policies. Some models may require attribution or commercial use licenses, while others may be more permissive. Additionally, ensure that the model’s training data is compatible with your intended use case and complies with relevant data protection laws.
The licensing landscape for LLMs spans from highly permissive to custom and restricted usage. Table 8.2 provides a summary of the licensing terms for some of the most popular open source LLMs. We observe two types of licenses:
Traditional Open Source:
Apache 2.0 (exemplified by Mistral AI’s models) offers comprehensive commercial usage rights with minimal restrictions
MIT License (used by Microsoft’s Phi-3) provides similar freedoms with simpler terms
Custom Commercial Licenses:
Meta’s LLaMA 3 allows free usage for applications serving under 700 million users
Alibaba’s Qwen2.5 permits free deployment for services with fewer than 100 million users
Both restrict using model outputs to train competing LLMs
Creator |
LLM |
License |
|---|---|---|
Meta AI |
LLaMA 3 |
Custom - Free if under 700M users, cannot use outputs to train other non-LLaMA LLMs |
Microsoft |
Phi-3 |
MIT |
Mistral AI |
Mistral |
Apache 2.0 |
Alibaba |
Qwen2.5 |
Custom - Free if under 100M users, cannot use outputs to train other non-Qwen LLMs |
Gemma |
Custom - Free with usage restrictions, models trained on outputs become Gemma derivatives |
|
DeepSeek |
DeepSeek-V2 |
Custom - Free with usage restrictions, models trained on outputs become DeepSeek derivatives |
When selecting an open-source LLM for deployment, practitioners must carefully evaluate licensing terms that align with intended usage (whether commercial, research, or other). While permissive licenses like Apache 2.0 and MIT allow broad usage rights, custom licenses may impose specific restrictions on commercial applications or model derivatives, making thorough license review essential for sustainable implementation.
The training data sources for LLMs represent another critical consideration. Models vary significantly in their training data foundations - some leverage purely public datasets while others incorporate proprietary or restricted content with the added complexity that public data does not mean free data. These data choices fundamentally impact not only model capabilities but also legal and regulatory compliance.
The legal landscape surrounding LLM training data has grown increasingly complex, particularly regarding copyright infringement concerns. The high-profile lawsuit between OpenAI and The New York Times [Review, 2024] serves as a pivotal example, where the Times claims its copyrighted materials were used without authorization to train language models. This litigation has far-reaching consequences for developers building LLM-powered applications. Should courts rule in favor of copyright holders, model providers may need to withdraw and retrain models containing protected content. These legal uncertainties introduce substantial complexity into LLM implementation strategies, demanding careful consideration during project planning phases.
Recent LLM releases demonstrate varying levels of data transparency. For instance, Qwen2.5’s approach [Qwen et al., 2024] illustrates common industry practices in both its achievements and limitations. On the training data scale front, Qwen2.5 does provide some transparency by discussing some training data methodology compared to previous versions such as expanding from 7 trillion to 18 trillion tokens, while implementing sophisticated quality filtering and carefully balancing domain representation through sampling adjustments.
However, like many commercial LLMs, Qwen2.5 exhibits transparency limitations. The report provides incomplete disclosure of data sources and limited information about the proportions of different data types used in training. The preprocessing methodologies remain unclear, and there is minimal discussion of potential biases that may exist in the training data.
Similarly, in the Llama 3 paper [AI, 2024c], Meta AI does share some details about the pre-training corpus stating simply stating that it was around 15T multilingual tokens, compared to 1.8T tokens for Llama 2. The exact sources of data used for pre-training and post-training are not explicitly listed.
These gaps in transparency reflect a broader industry challenge in balancing commercial interests with the need for openness and scientific reproducibility.
A significant advancement in open-source language model training data is HuggingFace’s release of the FineWeb datasets. In its first release [Penedo et al., 2024], FineWeb is made of a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. Additionally, data curation codebase and all of the models trained during our ablation experiments are made available. FineWeb is a fine example of an initiative that helps minimize the gap between proprietary and public knowledge.
8.2.4. Community Support¶
Community support plays a vital role in the open-source LLM ecosystem. Active communities contribute to model development, provide technical assistance, and share valuable resources. When evaluating open-source LLMs, the strength and engagement of the community should be a key consideration, as it directly impacts the model’s long-term viability and practical utility.
The popularity of different model families reflects their community adoption. In 2024, the Qwen and Llama families have emerged as clear favorites, with Qwen2.5-1.5B-Instruct alone representing 35% of total open source models downloads in 2024.
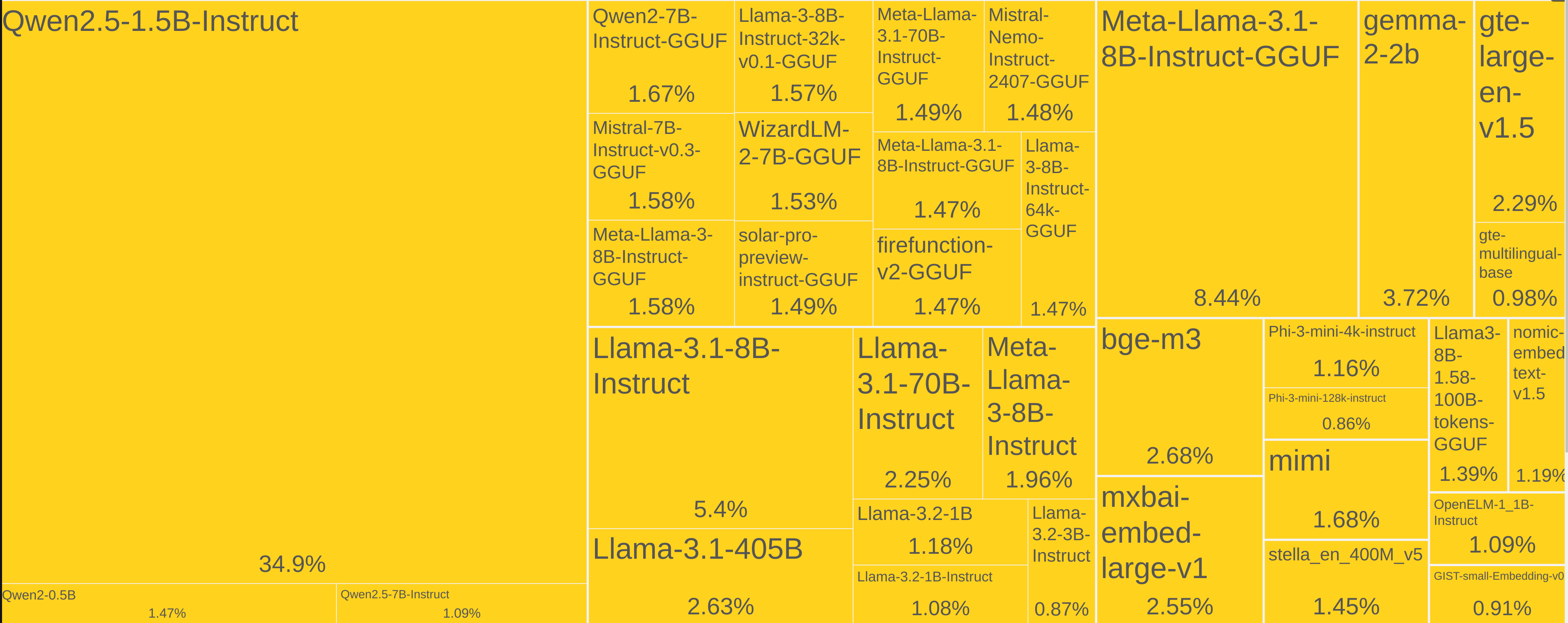
Fig. 8.10 Hugging Face Model Downloads in 2024 as of December 22 of the same year [HuggingFace, 2024t].¶
Strong communities accelerate model innovation through collective effort. When developers and researchers collaborate on model development, they create a powerful ecosystem of continuous improvement. Through transparent sharing of findings, they enable rapid development of novel applications and specialized model variants for specific domains. This collaborative environment naturally leads to the establishment of best practices and frameworks that benefit the entire community. The success of this community-driven approach is evident in models like Qwen2.5-1.5B-Instruct, which has spawned 200+ derivative models through post-training adaptations [Qwen, 2024b].
8.2.5. Customization¶
Model customization is an important consideration when selecting an open-source LLM. Adapting and fine-tuning to specific use cases can significantly impact practical utility and performance in production environments.
Model providers increasingly offer streamlined fine-tuning services. For example, Mistral demonstrates an accessible approach to model customization. The code below shows Mistral’s straightforward fine-tuning API. The example shows how to create and start a fine-tuning job with just a few lines of code. The fine-tuning job is configured with the base model “open-mistral-7b” and uses training and validation files from the Ultrachat dataset [HuggingFace, 2024u]. This API design makes it easy to experiment with model customization while maintaining control over the training process.
# create a fine-tuning job
created_jobs = client.fine_tuning.jobs.create(
model="open-mistral-7b",
training_files=[{"file_id": ultrachat_chunk_train.id, "weight": 1}],
validation_files=[ultrachat_chunk_eval.id],
hyperparameters={
"training_steps": 10,
"learning_rate":0.0001
},
auto_start=False
)
# start a fine-tuning job
client.fine_tuning.jobs.start(job_id = created_jobs.id)
created_jobs
For more comprehensive customization needs, Hugging Face’s Transformer Reinforcement Learning (TRL) toolkit provides robust capabilities for model adaptation. Built on the Transformers library, TRL supports [HuggingFace, 2024d]:
Supervised Fine-Tuning (SFT)
Reward Modeling (RM)
Proximal Policy Optimization (PPO)
Direct Preference Optimization (DPO)
In Case Study: Aligning a Language Model to a Policy, we will explore how to use TRL to fine-tune a model to align with user preferences.
Successful model customization demands managing critical resources throughout the development lifecycle. This includes rigorous dataset preparation and validation to ensure high-quality training data, careful configuration of training infrastructure to optimize computational resources, systematic experimentation iterations while managing associated costs, comprehensive performance evaluation frameworks to measure improvements, and thoughtful deployment architecture planning to ensure smooth production integration. Of course, actual cost of storage and inference should be taken into consideration. Table 8.3 shows as an example the cost of associated with fine-tuning Mistral models [AI, 2024a].
Model |
One-off training (/M tokens) |
Storage |
Input (/M tokens) |
Output (/M tokens) |
|---|---|---|---|---|
Mistral NeMo |
$1 |
$2 per month per model |
$0.15 |
$0.15 |
Mistral Large 24.11 |
$9 |
$4 per month per model |
$2 |
$6 |
Mistral Small |
$3 |
$2 per month per model |
$0.2 |
$0.6 |
Codestral |
$3 |
$2 per month per model |
$0.2 |
$0.6 |
Small language models can serve as a lightweight alternative to customization compared to large models. Recent research has shown that smaller models can achieve competitive performance compared to larger models [HuggingFace, 2024v, Zhao et al., 2024]. A noteworthy example is Hugging Face’s SmolLM2 [Allal et al., 2024], a family of compact language models designed with several key advantages:
Compact Sizes:
Available in three sizes: 135M, 360M, and 1.7B parameters
Small enough to run on-device and local hardware
Doesn’t require expensive GPU resources
Versatility:
Can perform a wide range of tasks despite small size
Supports text summarization, rewriting, and function calling
Can be used for multimodal applications (via SmolVLM)
Easy Integration and Customization:
Supports multiple frameworks like llama.cpp, MLX, MLC, and transformers.js
Can be fine-tuned using TRL and PEFT for custom applications
Provides pre-training and fine-tuning scripts for customization
Includes synthetic data pipelines for creating custom training data
These models address a crucial need in the AI ecosystem by making language models more accessible and practical for developers who need local, efficient solutions without compromising too much on capability. The provided tools and scripts for customization make it particularly valuable for developers who need to adapt the model for specific use cases or domains.
8.3. Tools for Local LLM Deployment¶
Local LLM deployment tools generally fall into two categories: inference-focused tools that prioritize performance and programmability for technical users requiring production-grade deployments, and user interface (UI) tools that emphasize accessibility through graphical interfaces for non-technical users, trading some performance for ease of use and broader adoption. In the following sections we will explore some of these tools discussing their features, capabilities, and trade-offs.
8.3.1. Serving Models¶
Serving an LLM model involves making it available for inference by setting up infrastructure to process requests and manage resources efficiently. This serving layer handles several key responsibilities, from loading model weights and managing compute resources to processing requests and optimizing performance. Let’s examine the core components of model serving:
Model Loading and Initialization
Loading the trained model weights and parameters into memory
Initializing any required runtime configurations and optimizations
Setting up inference pipelines and processing workflows
Resource Management
Allocating and managing system memory (RAM/VRAM) for model weights
Handling computational resources like CPU/GPU efficiently
Implementing caching and batching strategies where appropriate
Request Processing and Inference
Accepting input requests through defined interfaces
Converting input text into token vectors \(\mathbf{x} = [x_1, x_2, ..., x_n]\) through tokenization
Computing probability distributions \(P(x_{n+1}|x_1, x_2, ..., x_n; θ)\) for next tokens
Performing matrix multiplications and attention computations
Sampling each new token from the calculated probability distribution
Post-processing and returning responses
Performance Optimization
Implementing techniques like quantization to reduce memory usage
Optimizing inference speed through batching and caching
Managing concurrent requests and load balancing
Monitoring system resource utilization
The serving layer acts as the bridge between the LLM and applications while working on top of a hardware stack as shown in Fig. 8.11. Getting this layer right is crucial for building locally-served reliable AI-powered applications, as it directly impacts the end-user experience in terms of response times, reliability, and resource efficiency.

Fig. 8.11 Local Inference Server.¶
Model inference can be performed on Open Source models using cloud solutions such as Groq, Cerebras Systems, and SambaNova Systems. Here, we limit our scope to Open Source solutions that enable inference on local machines which includes consumer hardware. We will cover the following:
LLama.cpp: A highly optimized C++ implementation for running LLMs on consumer hardware
Llamafile: A self-contained executable format by Mozilla for easy model distribution and deployment
Ollama: A tool that simplifies running and managing local LLMs with Docker-like commands
Let’s explore each of these options in detail.
8.3.1.1. LLama.cpp¶
LLama.cpp [Gerganov and contributors, 2024a] is an MIT-licensed open source optimized implementation of the LLama model architecture designed to run efficiently on machines with limited memory.
Originally developed by Georgi Gerganov and today counting with hundreds of contributors, this C/C++ LLama version provides a simplified interface and advanced features that allow language models to run locally without overwhelming systems. With the ability to run in resource-constrained environments, LLama.cpp makes powerful language models more accessible and practical for a variety of applications.
In its “Manifesto” [Gerganov and others, 2023], the author highlights the significant potential in bringing AI from cloud to edge devices, emphasizing the importance of keeping development lightweight, experimental, and enjoyable rather than getting bogged down in complex engineering challenges. The author states a vision that emphasizes maintaining an exploratory, hacker-minded approach while building practical edge computing solutions highlighting the following core principles:
“Will remain open-source”
Focuses on simplicity and efficiency in codebase
Emphasizes quick prototyping over premature optimization
Aims to stay adaptable given rapid AI model improvements
Values practical experimentation over complex engineering
LLama.cpp implementation characteristics include:
Memory Efficiency: The main advantage of LLama.cpp is its ability to reduce memory requirements, allowing users to run large language models at the edge for instance offering ease of model quantization.
Computational Efficiency: Besides reducing memory usage, LLama.cpp also focuses on improving execution efficiency, using specific C++ code optimizations to accelerate the process.
Ease of Implementation: Although it’s a lighter solution, LLama.cpp doesn’t sacrifice result quality. It maintains the ability to generate texts and perform NLP tasks with high precision.
GGUF
GGUF (GPT-Generated Unified Format) [Gerganov and contributors, 2024b] is the latest model format used by LLama.cpp, replacing the older GGML format. It was designed specifically for efficient inference of large language models on consumer hardware. The key features that make GGUF particularly valuable include [IBM Think, 2024]:
Improved quantization: GGUF supports multiple quantization levels to reduce model size while preserving performance. Common quantization schemes that are supported by GGUF include:
2-bit quantization: Offers the highest compression, significantly reducing model size and inference speed, though with a potential impact on accuracy.
4-bit quantization: Balances compression and accuracy, making it suitable for many practical applications.
8-bit quantization: Provides good accuracy with moderate compression, widely used in various applications.
Metadata support: The format includes standardized metadata about model architecture, tokenization, and other properties
Memory mapping: Enables efficient loading of large models by mapping them directly from disk rather than loading entirely into RAM
Architecture-specific optimizations: Takes advantage of CPU/GPU specific instructions for faster inference
Versioning support: Includes proper versioning to handle format evolution and backwards compatibility
These capabilities make GGUF models significantly more practical for running LLMs locally compared to full-precision formats, often dramatically reducing memory requirements. Hugging Face hosts a growing collection of pre-converted GGUF models [HuggingFace, 2024x] and provides a tool (ggml-org/gguf-my-repo) to convert existing models to GGUF format, making it easier for developers to access and deploy optimized versions of popular language models.
Setup
Please follow the instructions from the LLama.cpp GitHub repository [Gerganov and contributors, 2024a] to install and compile the library.
Here, we will compile the library from source on a Linux machine with 8 jobs in parallel for enhanced performance (add the -j argument to run multiple jobs in parallel).
sudo apt install cmake
cmake -B build
cmake --build build --config Release -j 8
Python bindings are available through llama-cpp-python package [Betlen and contributors, 2024].
pip install llama-cpp-python
llama-cli
A comprehensive command line interface is available through llama-cli as demonstrated below, where we use the -cnv flag to run the model in a conversational mode. We will use Qwen/Qwen2.5-0.5B-Instruct-GGUF model. Download it from Hugging Face and place it in the llamacpp/models directory.
./build/bin/llama-cli -m ./models/qwen2.5-0.5b-instruct-q8_0.gguf -p "You are a helpful assistant - Be succinct." -cnv
As a result, you can interact with the model in the terminal as a chatbot.
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
system
You are a helpful assistant - Be succinct.
> What is the meaning of life?
The meaning of life is a philosophical question that has been debated and debated for thousands of years. Some people believe that the meaning of life is to seek personal fulfillment and happiness, while others believe that it is to find a purpose in life that aligns with one's values and beliefs. The answer may also vary depending on a person's cultural, religious, or personal background.
> Are LLMs more helpful than dangerous?
Yes, LLMs (Large Language Models) can be more helpful than dangerous in many cases. They are designed to assist with a wide range of tasks, from generating text to providing information. They can also be used to help with decision-making and problem-solving. However, like any tool, LLMs can be a tool of great power if not used responsibly and ethically. It is important to use LLMs for positive and beneficial purposes while being mindful of their potential to harm.
> Bye bye.
Goodbye! If you have any other questions, feel free to ask.
llama-server
llama-server is a server version of llama-cli that can be accessed via a web interface or API.
./build/bin/llama-server -m ./models/qwen2.5-0.5b-instruct-q8_0.gguf --port 8080
This will start a server on port 8080.
main: server is listening on http://127.0.0.1:8080 - starting the main loop
Now we can send a request as we would for any Cloud API but here instead send a request to our local server.
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer no-key" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant - Be succinct."
},
{
"role": "user",
"content": "What is the meaning of life?"
}
]
}'
We obtain a JSON response. As expected, assistant’s response is in content[0].message.content following OpenAI’s API format.
{
"choices":[
{
"finish_reason":"stop",
"index":0,
"message":{
"content":"The meaning of life is a question that has been debated throughout history. Some people believe it is to find happiness and purpose, while others believe it is to seek knowledge and knowledge. Ultimately, the meaning of life is a deeply personal and subjective question that cannot be answered universally.",
"role":"assistant"
}
}
],
"created":1734627879,
"model":"gpt-3.5-turbo",
"object":"chat.completion",
"usage":{
"completion_tokens":56,
"prompt_tokens":29,
"total_tokens":85
},
"id":"chatcmpl-5Wl2TZJZDmzuPvxwP2GceDR8XbPsyHfm",
"timings":{
"prompt_n":1,
"prompt_ms":48.132,
"prompt_per_token_ms":48.132,
"prompt_per_second":20.77619878666999,
"predicted_n":56,
"predicted_ms":1700.654,
"predicted_per_token_ms":30.36882142857143,
"predicted_per_second":32.92850867960208
}
}
Grammars
It is worth noting Llama.cpp provides a way to use grammars [Gerganov and contributors, 2024] to constrain the output of the model as demonstrated below. This is the same technique Ollama uses, a similar approach to Outlines’ to generate structured outputs from LLMs. See Chapter Structured Output for more details.
./build/bin/llama-cli -m ./models/qwen2.5-0.5b-instruct-q8_0.gguf --grammar-file grammars/json.gbnf -p 'Request: schedule a call at 8pm; Command:'
# {"appointmentTime": "8pm", "appointmentDetails": "schedule a a call"}
Python
A handy Python binding [Betlen and contributors, 2024] is available for LLama.cpp, which by default returns chat completions in OpenAI’s API chat format as below. The package is very comprehensive supporting JSON Mode, function calling, multi-modal models and more.
MODEL_PATH = "./models/qwen2.5-0.5b-instruct-q8_0.gguf"
from llama_cpp import Llama
llm = Llama(
model_path=MODEL_PATH
)
response = llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a helpful assistant - Be succinct."},
{
"role": "user",
"content": "What is the meaning of life?"
}
]
)
response['choices'][0]['message']['content']
'The meaning of life is a philosophical question that has been debated by philosophers, scientists, and individuals throughout history. Some people believe that the meaning of life is to find happiness and fulfillment, while others believe that it is to seek knowledge and understanding of the universe. Ultimately, the meaning of life is a personal and subjective question that varies from person to person.'
Alternatively, we could have pulled our model directly from Hugging Face Hub:
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="Qwen/Qwen2-0.5B-Instruct-GGUF",
verbose=False
)
8.3.1.2. Llamafile¶
Developed by Occupy Wall Street’s former activist, Justine Tunney, Llamafile [Mozilla Ocho, 2024] is an Appache 2.0 licensed open source tool that combines the power of LLama.cpp with Cosmopolitan Libc, a universal C standard library that allows creating portable executables compatible with multiple operating systems.
In this way, Llamafile reduces all the complexity of LLMs to a single executable file (called a “llamafile”) that runs locally without installation. Key advantages of Llamafile over plain Llama.cpp include:
Zero Installation/Configuration
Llamafile: Single executable file that works immediately
Llama.cpp: Requires compilation, dependency management, and proper setup of your development environment
Cross-Platform Portability
Llamafile: One binary works across Windows, macOS, and Linux without modification
Llama.cpp: Needs to be compiled separately for each operating system, managing platform-specific dependencies
Distribution Simplicity
Llamafile: Share a single file that just works
Llama.cpp: Need to distribute source code or platform-specific binaries along with setup instructions
Besides simplifying the use of LLMs, Llamafile delivers durability as model weights remain usable and reproducible over time, even as new formats and models are developed. In summary, Llamafile trades some optimization potential from LLama.cpp for improved ease of use and portability.
A large collection of Llamafiles can be found on HuggingFace [HuggingFace, 2024x]. All you need to do is:
Download a llamafile from HuggingFace
Make the file executable
Run the file
Here’s a simple bash script that shows all 3 setup steps for running TinyLlama-1.1B locally:
# Download a llamafile from HuggingFace
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Make the file executable. On Windows, instead just rename the file to end in ".exe".
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Start the model server. Listens at http://localhost:8080 by default.
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser
As a result, a model server is running on http://localhost:8080. And we can use it as demonstrated in the previous section.
8.3.1.3. Ollama¶
Ollama is a lightweight, MIT-licensed open-source tool for running LLMs locally. It provides a simple interface for interacting with a wide range of language models, including popular models like Llama 3.1 and Llama 3.2. Ollama is designed to be easy to install and use, making it a popular choice for developers who want to run LLMs locally without the need for extensive setup or configuration. Ollama’s key advantages include:
Model Management
Built-in model registry and easy downloading of popular models
Simple commands to list, remove, and switch between models
Handles model updates and versions automatically
API First Design
Provides a REST API out of the box
Easy integration with applications and services
Built-in support for different programming languages
Container Support
Native Docker integration
Easy deployment in containerized environments
Better resource isolation and management
User Experience
More “app-like” experience with system tray integration
Simple CLI commands that feel familiar to developers
No need to deal with file permissions or executables
Despite its advantages, Ollama comes with some trade-offs: it provides less low-level control compared to Llama.cpp, requires proper platform-specific installation unlike the portable Llamafile, and introduces additional resource overhead from running services that aren’t present in bare Llama.cpp implementations.
Setup
First, install Ollama on your machine. You can do this through the terminal with the following command:
curl -sSfL https://ollama.com/download | sh
Or download the installer directly from https://ollama.com
Inference
After installation, you can download a pre-trained model. For example, to download the qwen2:0.5b model, run in terminal:
ollama run qwen2:0.5b
To see more details about the model, just run:
ollama show qwen2:0.5b
To stop the model server, run:
ollama stop qwen2:0.5b
To see all models you’ve downloaded:
ollama list
Server
As in Llama.cpp and Llamafile, Ollama can be run as a server.
ollama serve
ollama run qwen2:0.5b
And then we can send requests to the server.
curl http://localhost:11434/api/chat -d '{
"model": "qwen2:0.5b",
"messages": [
{ "role": "user", "content": "What is the meaning of life?" }
]
}'
Python
A Python binding is also available for Ollama.
pip install ollama
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='qwen2:0.5b', messages=[
{
'role': 'user',
'content': 'What is the meaning of life?',
},
])
print(response.message.content)
8.3.1.4. Comparison¶
Each solution offers distinct advantages and tradeoffs that make them suitable for different use cases. At a high-level, Ollama is the easiest to install and use and has become the most popular choice for your average use case, Llamafile is the easiest to distribute and a good choice when portability is a priority, and Llama.cpp is the most customizable and performant solution as summarized in Table 8.4.
Feature |
Ollama |
Llamafile |
Llama.cpp |
|---|---|---|---|
Installation |
Package manager |
No installation needed |
Compilation / Package manager |
Model Management |
Built-in registry |
Manual download |
Manual download |
Containerization |
Native support |
Possible with configuration |
Possible with configuration |
Portability |
Per-platform install |
Single executable |
Needs compilation |
Choose Ollama if you:
Want a user-friendly way to experiment with different models
Need API integration capabilities
Plan to use Docker in your workflow
Prefer a managed approach to model handling
Choose Llamafile if you:
Need maximum portability
Want zero installation
Prefer a self-contained solution
Choose Llama.cpp if you:
Need maximum performance
Want low-level control
Are building a custom solution
8.3.2. UI¶
There is a growing number of UI tools for local LLM deployment that aim at providing a more user-friendly experience. Ranging from closed-source to open-source solutions across a range of features and capabilities. We will discuss LM Studio, Jan, and OpenWebUI.
8.3.2.1. LM Studio¶
LM Studio [LM Studio, 2024] is a closed-source GUI for running LLMs locally. In the context of local deployment, LM Studio positions itself as a more user-friendly, feature-rich solution compared to the other tools. It’s particularly valuable for developers transitioning from cloud APIs to local deployment, and for users who prefer graphical interfaces over command-line tools. Key Features of LM Studio include:
Model Parameter Customization: Allows adjusting temperature, maximum tokens, frequency penalty, and other settings
Chat History: Enables saving prompts for later use
Cross-platform: Available on Linux, Mac, and Windows
AI Chat and Playground: Chat with LLMs and experiment with multiple models loaded simultaneously
Fig. 8.12 and Fig. 8.13 show LM Studio’s chat interface and server, respectively.
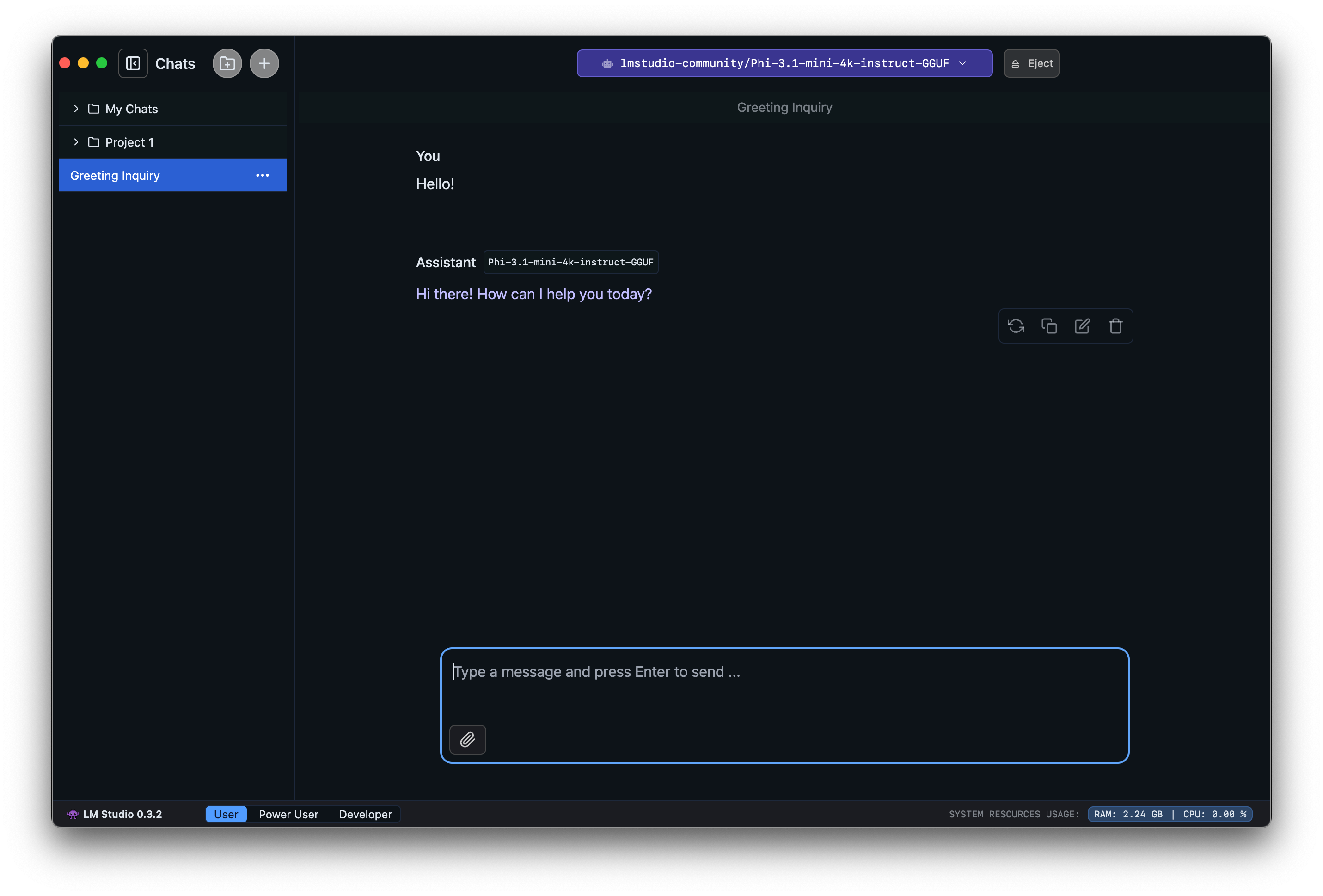
Fig. 8.12 LM Studio Chat Interface.¶
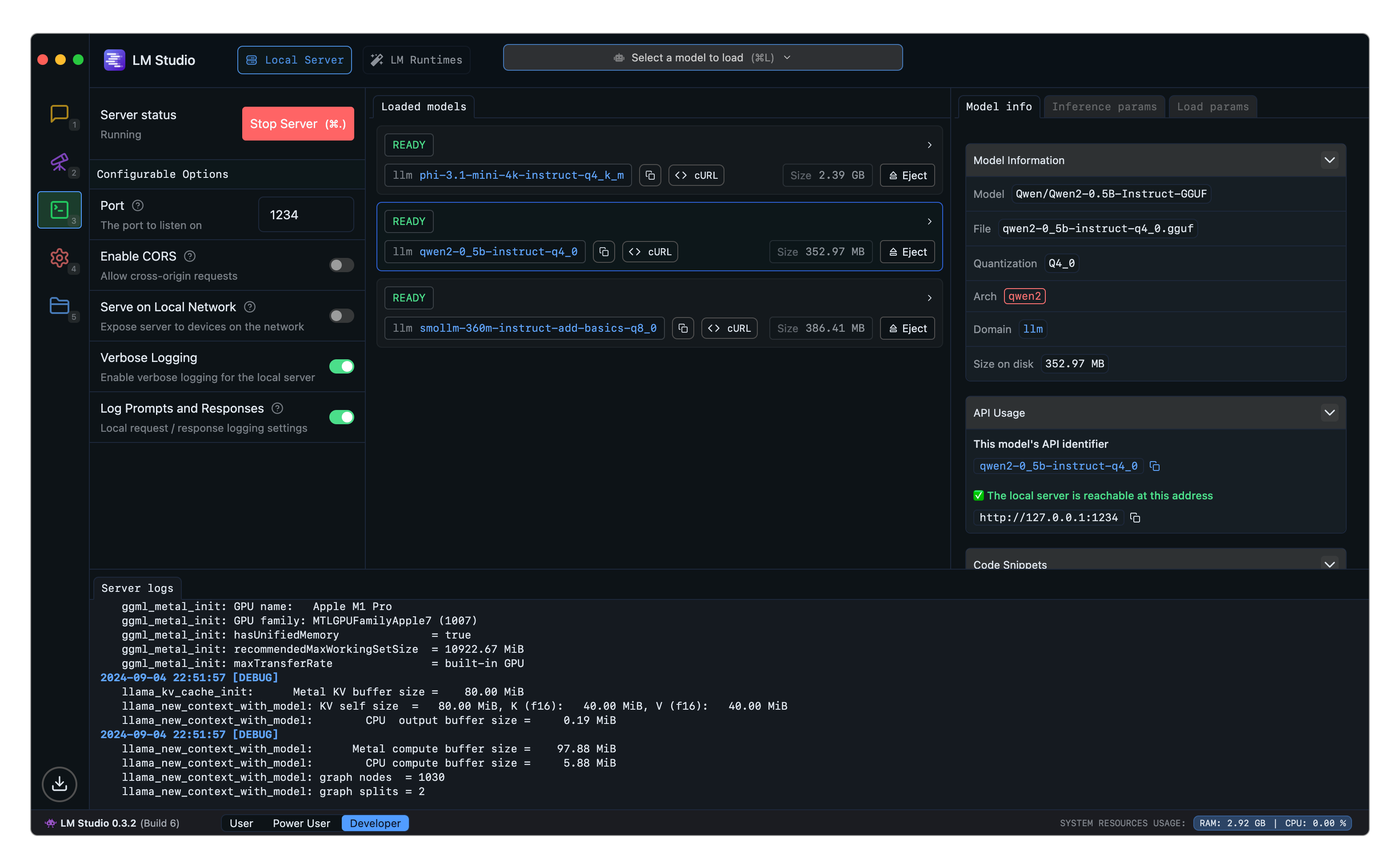
Fig. 8.13 LM Studio Server.¶
One important feature of LM Studio is that it provides machine specification verification capabilities, checking computer specifications like GPU and memory to report compatible models therefore helping users choose the right model. It also includes a local inference server for developers that allows setting up a local HTTP server similar to OpenAI’s API. Importantly, LM Studio’s OpenAI API compatibility is a particularly strong feature for developers looking to move their applications from cloud to local deployment with minimal code changes.
8.3.2.2. Jan¶
Jan is an open source ChatGPT-alternative that runs local models. Its model’s library contains popular LLMs like Llama, Gemma, Mistral, or Qwen. Key Features of Jan include:
User-Friendly Interface: Run AI models with just a few clicks
Accessibility: Intuitive platform for both beginners and experts
Local Server: Local API Server with OpenAI-equivalent API
Model Hub Integration: Easy access to various models with ease of import from LM Studio
Cross-Platform Support: Works across different operating systems
Jan has a default C++ inference server built on top of llama.cpp and provides an OpenAI-compatible API. Jan natively supports GGUF (through a llama.cpp engine) and TensorRT (through a TRT-LLM engine). HuggingFace models can be downloaded directly using the model’s ID or URL. User can optionally use cloud-based models (e.g. GPT, Claude models). Fig. 8.14 shows Jan’s chat interface.
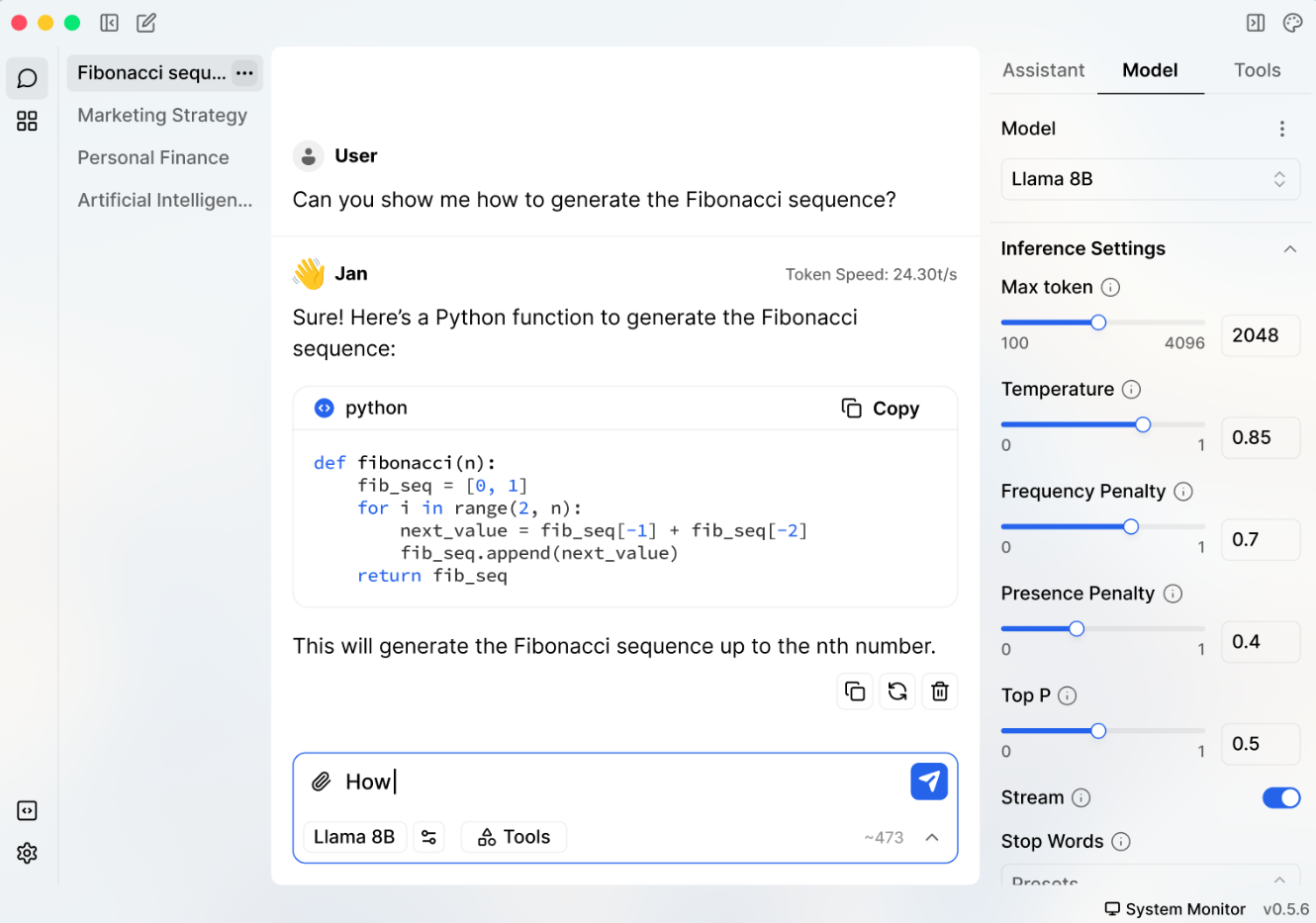
Fig. 8.14 Jan Chat Interface.¶
8.3.2.3. Open WebUI¶
Open WebUI is an open-source web interface designed to enhance the local AI model experience, particularly for Ollama and OpenAI-compatible APIs. It aims to provide enterprise-grade features while maintaining user-friendliness. OpenWebUI’s core features include:
Advanced User Interface
Full markdown and LaTeX support
Voice and video call capabilities
Mobile-friendly with PWA support
Multi-model chat interface
Enterprise Features
Role-based access control
User groups and permissions
Usage monitoring
Team collaboration tools
Advanced Capabilities
Local RAG (Retrieval Augmented Generation)
Web search integration
Image generation support
Python function calling
Document library
Custom model building
Fig. 8.15 shows Open WebUI’s chat interface.
Fig. 8.15 Open WebUI Chat Interface.¶
While Open WebUI offers advanced capabilities including RAG and multi-model support, these features require more system resources than simpler alternatives. Open WebUI is likely to be adopted by enterprise users who require advanced features and a more user-friendly interface.
8.3.2.4. Comparison¶
LM Studio excels at providing individual developers with a smooth transition from cloud APIs to local deployment, offering an intuitive interface and robust API compatibility, however it is closed-source. Jan focuses on simplicity and accessibility, making it ideal for personal use and basic deployments while maintaining open-source benefits. OpenWebUI makes additional features available to enterprise users and teams requiring advanced features like RAG, collaboration tools, and granular access controls, though this may come at the cost of increased complexity and resource requirements. We compare the three tools in Table 8.5.
Feature Category |
LM Studio |
Jan |
OpenWebUI |
|---|---|---|---|
Licensing |
Closed Source |
Open Source |
Open Source |
Setup Complexity |
Medium |
Easy |
Complex |
Resource Usage |
High |
Medium |
High |
Target Users |
Individual/Developers |
Individuals |
Enterprise/Teams |
UI Features |
- Full GUI |
- Simple GUI |
- Advanced GUI |
Model Support |
- Multiple models |
- Multiple models |
- Multi-model chat |
API Features |
- OpenAI compatible |
- Basic OpenAI compatible |
- Multiple API support |
Enterprise Features |
Limited |
None |
- RBAC |
Advanced Features |
- Parameter visualization |
- Basic chat |
- RAG support |
Best For |
- Individual developers |
- Personal use |
- Enterprise use |
8.4. Case Study: The Effect of Quantization on LLM Performance¶
This case study examines how different quantization [HuggingFace, 2024s] levels affect the performance of language models running locally. Quantization is a crucial technique for reducing model size and memory footprint while enhancing inference speed, but it comes with potential tradeoffs in model quality. Understanding these tradeoffs is essential for practitioners deploying LLMs in resource-constrained environments.
Using the Qwen 2.5 0.5B model as our baseline, we’ll compare four variants:
The base fp16 model (no quantization)
Q2_K quantization (highest compression, lowest precision)
Q4_K quantization (balanced compression/precision)
Q6_K quantization (lowest compression, highest precision)
The analysis will focus on three key types of metrics:
Quality-based:
Perplexity - to measure how well the model predicts text
KL divergence - to quantify differences in probability distributions against base model
Resource/Performance-based:
Prompt (tokens/second) - to assess impact in throughput
Text Generation (tokens/second) - to assess impact in text generation performance
Model Size (MiB) - to assess impact in memory footprint
While we will focus on the Qwen 2.5 0.5B model, the same analysis can be applied to other models. These insights will help practitioners make informed decisions about quantization strategies based on their specific requirements for model performance and resource usage.
8.4.1. Prompts Dataset¶
To evaluate the impact of quantization on model performance, we first need a set of prompts that will serve as input data for our experiments. We’ll construct a dataset from WikiText-2 [Salesforce, 2024], which contains Wikipedia excerpts.
In our experiments, we will use a total of NUM_PROMPTS prompts that vary in length from MIN_PROMPT_LENGTH to MAX_PROMPT_LENGTH tokens. Using a fixed set of prompts ensures consistent evaluation across model variants and enables direct comparison of metrics like perplexity and throughput.
NUM_PROMPTS = 100
MIN_PROMPT_LENGTH = 100
MAX_PROMPT_LENGTH = 1000
import datasets
input_texts_raw = datasets.load_dataset("Salesforce/wikitext", "wikitext-2-raw-v1", split="train")["text"]
input_texts = [s for s in input_texts_raw if s!='' and len(s) > MIN_PROMPT_LENGTH and len(s) < MAX_PROMPT_LENGTH][:NUM_PROMPTS]
len(input_texts)
100
print(input_texts[1])
The game began development in 2010 , carrying over a large portion of the work done on Valkyria Chronicles II . While it retained the standard features of the series , it also underwent multiple adjustments , such as making the game more forgiving for series newcomers . Character designer Raita Honjou and composer Hitoshi Sakimoto both returned from previous entries , along with Valkyria Chronicles II director Takeshi Ozawa . A large team of writers handled the script . The game 's opening theme was sung by May 'n .
with open('../data/local/prompts.txt', 'w') as f:
for text in input_texts:
# Escape any quotes in the text and wrap in quotes
escaped_text = text.replace('"', '\\"')
f.write(f'"{escaped_text}"\n')
8.4.2. Quantization¶
We can quantize a model using the llama-quantize CLI. For instance, to quantize the Qwen 2.5 0.5B model to Q4_K, we can run the following command:
./llama-quantize -m ./models/qwen2.5-0.5b-instruct-fp16.gguf ./models/qwen2.5-0.5b-instruct-q8_0.gguf Q4_K
Table 8.6 describes the key quantization levels used in this study [HuggingFace, 2024w], where:
q is the quantized value
block_scale is the scaling factor for the block (with bit width in parentheses)
block_min is the block minimum value (with bit width in parentheses)
Quantization |
Description |
Bits per Weight |
Formula |
|---|---|---|---|
Q2_K |
2-bit quantization with 16 weights per block in 16-block superblocks |
2.5625 |
w = q * block_scale(4-bit) + block_min(4-bit) |
Q4_K |
4-bit quantization with 32 weights per block in 8-block superblocks |
4.5 |
w = q * block_scale(6-bit) + block_min(6-bit) |
Q6_K |
6-bit quantization with 16 weights per block in 16-block superblocks |
6.5625 |
w = q * block_scale(8-bit) |
Each quantization level represents a different tradeoff between model size and accuracy. Q2_K provides the highest compression but potentially lower accuracy, while Q6_K maintains better accuracy at the cost of larger model size. The base model is 16-bit standard IEEE 754 half-precision floating-point number.
8.4.3. Benchmarking¶
We will measure quantized model “quality” by means of perplexity and KL Divergence.
Perplexity
Perplexity is a common metric for evaluating language models that measures how well a model predicts a sample of text. Lower perplexity indicates better prediction (less “perplexed” by the text).
Recall that for a sequence of N tokens, perplexity is defined as:
where:
\(P(x_i|x_{<i})\) is the probability the model \(B\) with tokenized sequence \(X\) assigns to token \(x_i\) given the previous tokens \(x_{<i}\)
\(N\) is the total number of tokens in the sequence
To evaluate quantization quality, we first calculate perplexity scores for both the base model and quantized variants. We then compute the ratio of quantized to base perplexity and average it across all prompt samples as follows:
We also calculate the correlation between the log perplexities of the quantized and base models:
These are two simple metrics to evaluate how much worse the quantized model performs on an intrinsic basis which we then can compare to the base model’s perplexities.
Arguably, KL Divergence is a better metric enabling direct comparison of relative performance instead of intrinsic performance.
KL Divergence
Recall that Kullback-Leibler (KL) Divergence (or Cross-Entropy) measures how one probability distribution differs from another reference distribution. For comparing logits between a base model (B) and quantized model (Q), we can calculate the KL divergence as follows:
where:
\(P(i)\) and \(Q(i)\) are the softmax probabilities derived from the logits
The sum is taken over all tokens in the vocabulary
Implementation
We will use LLama.cpp’s llama-perplexity CLI to calculate perplexity and KL divergence. The first step is to generate the logits for the base model, which will serve as the reference distribution. For instance, below we pass our input prompts (prompts.txt) and generate the logits for the base model qwen2.5-0.5b-instruct-fp16.gguf which will be saved in logits.kld.
./build/bin/llama-perplexity -m ./models/qwen2.5-0.5b-instruct-fp16.gguf --kl-divergence-base ../logits.kld -f ../prompts.txt
Next, we generate KL-Divergence and perplexity stats for quantized model qwen2.5-0.5b-instruct-q2_k.gguf against base model logits logits.kld.
./build/bin/llama-perplexity -m ./models/qwen2.5-0.5b-instruct-q2_k.gguf -f ../prompts.txt --kl-divergence-base ../logits.kld --kl-divergence &> ../q2_kresults.txt
We perform this process for each quantization level studied (Q2_K, Q4_K, Q6_K).
8.4.4. Results¶
The KL divergence and perplexity results in Fig. 8.17 and Fig. 8.16 provide insights into model quality across different quantization levels. Q6 maintains near-perfect correlation (99.90%) with the base model and minimal KL divergence (0.004), indicating very close distribution matching. Q2’s higher KL divergence (0.112) and lower correlation (98.31%) quantify its increased deviation from the base model’s behavior.
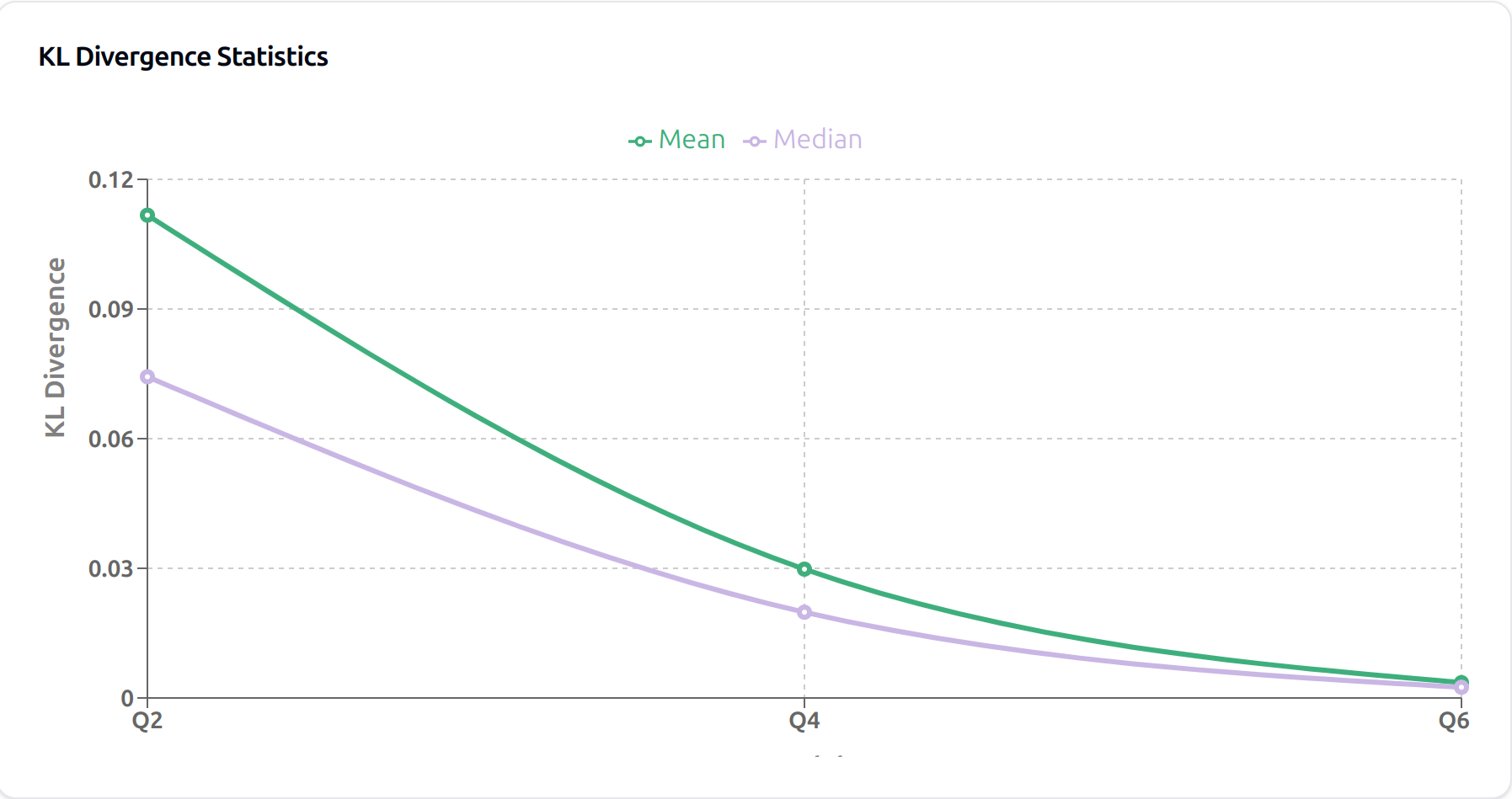
Fig. 8.16 KL Divergence results for Quantization Q2, Q4, and Q6 quantized models.¶
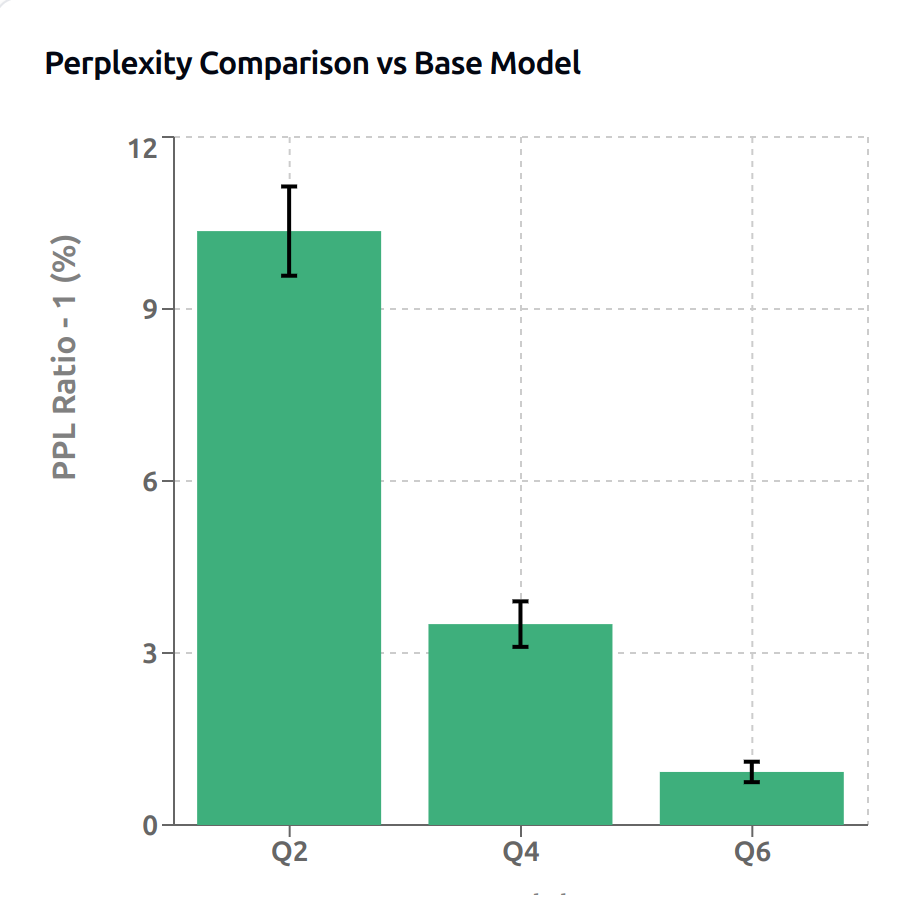
Fig. 8.17 Perplexity results for Quantization Q2, Q4, and Q6 quantized models.¶
From Table 8.7, we observe that the Q2 model achieves the smallest size at 390 MiB (67% reduction from base) with prompt throughput of 81 tokens/s, but has the highest perplexity degradation at 10.36%. The Q4 model offers a better balance, with good size savings (60% reduction) and only 3.5% perplexity loss. Q6 comes closest to matching the base model’s performance with just 0.93% perplexity degradation, while still providing 47% size reduction.
Model |
Size (MiB) |
Prompt Throughput (tokens/s) |
PPL Ratio - 1 (%) |
Correlation (%) |
KL Divergence (Mean) |
|---|---|---|---|---|---|
Q2 |
390.28 |
81.32 |
10.36 ± 0.78 |
98.31 |
0.112 ± 0.002 |
Q4 |
462.96 |
77.08 |
3.50 ± 0.40 |
99.50 |
0.030 ± 0.001 |
Q6 |
614.58 |
87.55 |
0.93 ± 0.18 |
99.90 |
0.004 ± 0.000 |
Base |
1,170.00 |
94.39 |
- |
- |
- |
Next, we benchmark text generation (inference) performance using llama-bench across all models:
./build/bin/llama-bench -r 10 -t 4 -m ./models/qwen2.5-0.5b-instruct-fp16.gguf -m ./models/qwen2.5-0.5b-instruct-q2_k.gguf -m ./models/qwen2.5-0.5b-instruct-q4_k_m.gguf -m ./models/qwen2.5-0.5b-instruct-q6_k.gguf
The benchmark parameters are:
-r 10: Run 10 iterations for each model-t 4: Use 4 threads-m: Specify model paths for base FP16 model and Q2, Q4, Q6 quantized versions
This runs text generation on a default benchmark of 128 tokens generation length (configurable via -g parameter).
Results in Fig. 8.18 indicate the base model delivers text generation performance at 19.73 tokens/s, while the most aggressively quantized Q2 model (390.28 MiB) delivers the highest throughput at 42.62 tokens/s, representing a 2.16x speedup. This pattern continues across Q4 (462.96 MiB, 38.38 tokens/s) and Q6 (614.58 MiB, 35.43 tokens/s), which presents a 1.85x and 1.79x speedup, respectively.
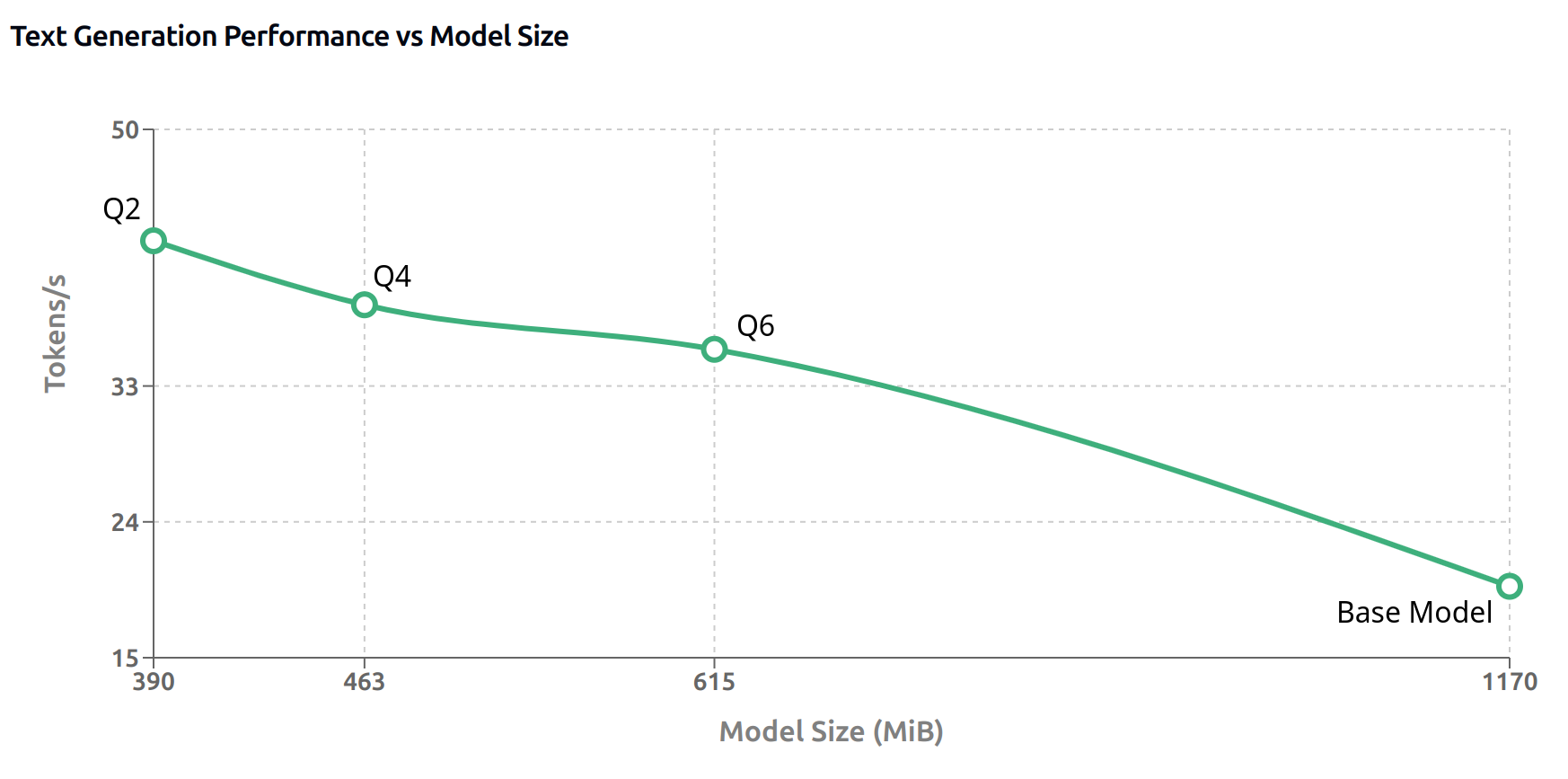
Fig. 8.18 Text Generation Performance results for Quantization Q2, Q4, Q6 and base models.¶
Benchmarking was performed on Ubuntu 24.04 LTS for x86_64-linux-gnu on commodity hardware (Table 8.8) with no dedicated GPU demonstrating the feasibility of running LLMs locally by nearly everyone with a personal computer thanks to LLama.cpp.
Device |
Description |
|---|---|
processor |
Intel(R) Core(TM) i7-8550U CPU @ 1 |
memory |
15GiB System memory |
storage |
Samsung SSD 970 EVO Plus 500GB |
8.4.5. Takeaways¶
The quantization analysis of the Qwen 2.5 0.5B model demonstrates a clear trade-off among model size, inference speed, and prediction quality. While the base model (1170 MiB) maintains the highest accuracy it operates at the lowest text generation and prompt throughput of 19.73 tokens/s and 94.39 tokens/s, respectively. In contrast, the Q2_K quantization achieves significant size reduction (67%) and the highest throughput (42.62 tokens/s), but exhibits the largest quality degradation with a 10.36% perplexity increase and lowest KL divergence among quantized models. Q4_K emerges as a compelling middle ground, offering substantial size reduction (60%) and strong text generation and prompt throughput performance (38.38 tokens/s and 77.08 tokens/s, respectively), while maintaining good model quality with only 3.5% perplexity degradation and middle-ground KL divergence level.
These results, achieved on commodity CPU hardware, demonstrate that quantization can significantly improve inference speed and reduce model size while maintaining acceptable quality thresholds, making large language models more accessible for resource-constrained environments.
It is important to note that these results are not meant to be exhaustive and are only meant to provide a general idea of the trade-offs involved in quantization. Targeted benchmarks should be performed for specific use cases and models to best reflect real-world performance.
8.5. Conclusion¶
Running open source language models locally represents a compelling proposition in how we interact with AI technology. The transition from cloud-based to local deployment offers important advantages in terms of privacy, cost control, and customization flexibility, while introducing important technical considerations around resource management and performance optimization. The growing ecosystem of tools and frameworks, from low-level libraries like llama.cpp to user-friendly interfaces like LM Studio and Jan, has made local deployment increasingly accessible to both individual developers and organizations.
Our case study demonstrated that quantization can significantly improve inference speed and reduce model size while maintaining acceptable quality thresholds, making large language models more accessible for resource-constrained environments. As demonstrated in our case study with the Qwen 2.5 0.5B model, practitioners can achieve significant reductions in model size and improvements in inference speed while maintaining acceptable performance levels. The Q4_K quantization scheme emerged as a particularly effective compromise, offering substantial size reduction (60%) and strong throughput while limiting quality degradation to just 3.5% in perplexity measures.
Looking ahead, the continued development of open source models and deployment tools suggests a future where local AI deployment becomes increasingly viable and sophisticated. The success of open source models like Qwen and Llama, combined with improvements in local model serving and techniques couple with efficient small language models (SLMs), indicate that local deployment will likely play an increasingly important role in the AI landscape. However, practitioners must carefully evaluate their specific requirements across dimensions like task suitability, resource constraints, and performance needs when choosing between local and cloud-based deployment strategies.

@misc{tharsistpsouza2024tamingllms,
author = {Tharsis T. P. Souza},
title = {Taming LLMs: A Practical Guide to LLM Pitfalls with Open Source Software},
year = {2024},
chapter = {Local LLMs in Practice},
journal = {GitHub repository},
url = {https://github.com/souzatharsis/tamingLLMs)
}
8.6. References¶
Meta AI. The llama 3 herd of models. 2024c. URL: https://arxiv.org/abs/2407.21783, arXiv:2407.21783.
Mistral AI. Mistral technology and pricing. https://mistral.ai/technology/#pricing, 2024a. Accessed: 2024.
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Lewis Tunstall, Agustín Piqueres, Andres Marafioti, Cyril Zakka, Leandro von Werra, and Thomas Wolf. Smollm2 - with great data, comes great performance. 2024.
Khalid Alnajjar and others. Toxigen dataset. Papers with Code Dataset, 2024. Dataset for evaluating and mitigating toxic language generation in language models. URL: https://paperswithcode.com/dataset/toxigen.
Artificial Analysis. Llm provider leaderboards. https://artificialanalysis.ai/leaderboards/providers, 2024. Accessed: 2024.
Artificial Analysis. Llm provider leaderboards. https://artificialanalysis.ai/leaderboards/providers, 2024. Accessed: 2024.
Artificial Analysis. Methodology. https://artificialanalysis.ai/methodology, 2024. Accessed: December 22, 2024.
Andrei Betlen and contributors. Llama-cpp-python. GitHub Repository, 2024. Python bindings for llama.cpp library enabling high-performance inference of LLaMA models. URL: https://github.com/abetlen/llama-cpp-python.
DeepSeek. Deepseek-v3 technical report. Technical Report, 2024. URL: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf.
Georgi Gerganov and contributors. Llama.cpp grammars documentation. GitHub Repository, 2024. Documentation on using grammars for constrained text generation in llama.cpp. URL: https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md.
Georgi Gerganov and contributors. Llama.cpp. GitHub Repository, 2024a. High-performance inference of LLaMA models in pure C/C++. URL: https://github.com/ggerganov/llama.cpp.
Georgi Gerganov and contributors. Gguf file format specification. GitHub Repository, 2024b. Technical specification of the GGUF file format for efficient model storage and inference. URL: https://github.com/ggerganov/ggml/blob/master/docs/gguf.md.
Georgi Gerganov and others. Quantization of llama models - discussion. GitHub Discussion, 2023. Discussion thread about quantization techniques and tradeoffs in llama.cpp. URL: https://github.com/ggerganov/llama.cpp/discussions/205.
HuggingFace. Trl. 2024d. TRL. URL: https://huggingface.co/docs/trl/en/index.
HuggingFace. Quantization in optimum. https://huggingface.co/docs/optimum/en/concept_guides/quantization, 2024s. Accessed: 2024.
HuggingFace. Open source ai year in review 2024. https://huggingface.co/spaces/huggingface/open-source-ai-year-in-review-2024, 2024t. Accessed: 2024.
HuggingFace. Ultrachat-200k dataset. 2024u. Accessed: 2024. URL: https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k.
HuggingFace. Scaling test time compute. 2024v. Accessed: 2024. URL: https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute.
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, and others. Qwen2.5 - coder technical report. arXiv preprint arXiv:2409.12186, 2024.
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: measuring how models mimic human falsehoods. 2022. URL: https://arxiv.org/abs/2109.07958, arXiv:2109.07958.
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: decanting the web for the finest text data at scale. 2024. URL: https://arxiv.org/abs/2406.17557, arXiv:2406.17557.
Qwen. Qwen2.5-1.5b-instruct. 2024b. Accessed: December 22, 2024. URL: https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct.
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical report. 2024. URL: https://arxiv.org/abs/2412.15115, arXiv:2412.15115.
Harvard Law Review. Nyt v. openai: the times's about-face. https://harvardlawreview.org/blog/2024/04/nyt-v-openai-the-timess-about-face/, 2024. Accessed: 2024.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: open foundation and fine-tuned chat models. 2023. URL: https://arxiv.org/abs/2307.09288, arXiv:2307.09288.
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, and Devvret Rishi. Lora land: 310 fine-tuned llms that rival gpt-4, a technical report. 2024. URL: https://arxiv.org/abs/2405.00732, arXiv:2405.00732.
HuggingFace. Gguf quantization types. Online Documentation, 2024w. Documentation on different quantization types available for GGUF models. URL: https://huggingface.co/docs/hub/gguf#quantization-types.
HuggingFace. Gguf models on huggingface. Online Repository, 2024x. Collection of models in GGUF format for efficient local inference. URL: https://huggingface.co/models?search=gguf.
HuggingFace. Llamafile models on huggingface. Online Repository, 2024x. Collection of models compatible with Mozilla's llamafile format. URL: https://huggingface.co/models?library=llamafile.
IBM Think. Gguf vs ggml: what's the difference? 2024. Comparison of GGUF and GGML model formats. URL: https://www.ibm.com/think/topics/gguf-versus-ggml.
LM Studio. Lm studio - discover, download, and run local llms. Website, 2024. Desktop application for discovering, downloading and running local language models. URL: https://lmstudio.ai/.
Meta AI. Llama-2-70b-chat-hf. HuggingFace Model, 2024c. 70 billion parameter chat model from Meta's Llama 2 family. URL: https://huggingface.co/meta-llama/Llama-2-70b-chat-hf.
Mozilla Ocho. Llamafile: distribute and run llms with a single file. GitHub Repository, 2024. Tool for packaging and distributing LLMs as self-contained executables. URL: https://github.com/Mozilla-Ocho/llamafile.
Salesforce. Wikitext dataset. HuggingFace Dataset, 2024. Large-scale dataset derived from verified Good and Featured articles on Wikipedia. URL: https://huggingface.co/datasets/Salesforce/wikitext.