9. The Falling Cost Paradox¶
It is a confusion of ideas to suppose that the economical use of fuel is equivalent to diminished consumption.
The very contrary is the truth.—William Stanley Jevons
Note
This Chapter is Work-in-Progress.
9.1. Why Optimization Matters More Than Ever¶
According to recent analysis from a16z [Andreessen Horowitz, 2024], the cost of LLM inference is decreasing by approximately 10x every year - a rate that outpaces even Moore’s Law in the PC revolution or Edholm’s Law during the bandwidth explosion of the dot-com era.
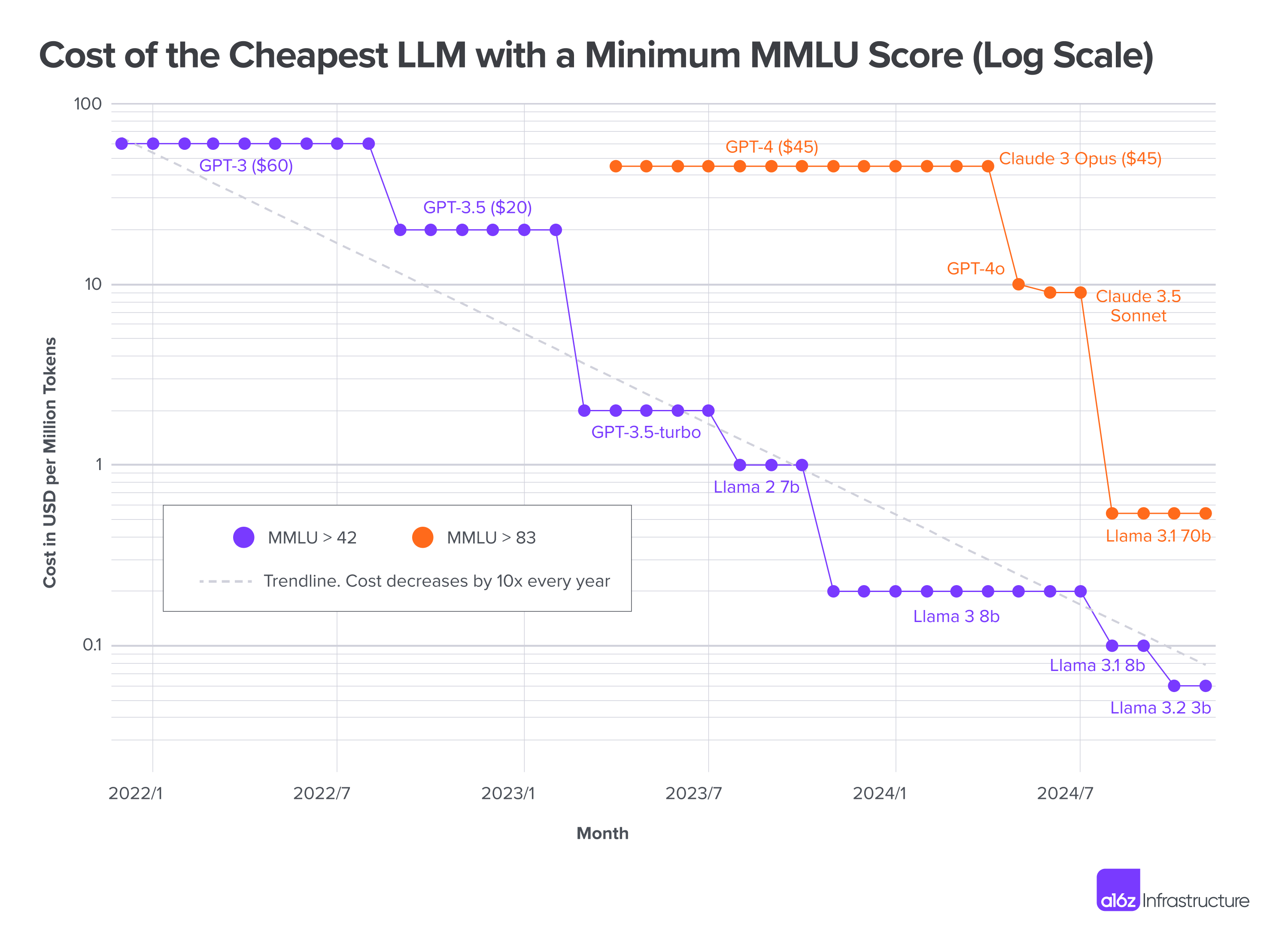
Fig. 9.1 LLMflation [Andreessen Horowitz, 2024]: The cost of LLM inference is decreasing by approximately 10x every year.¶
A model achieving an MMLU score of 42 that cost \(60 per million tokens in late 2021 can now be run for just \)0.06 per million tokens. For higher-capability models scoring 83 on MMLU, prices have fallen by a factor of 62 since GPT-4’s introduction in March 2023.
This dramatic decline stems from multiple compounding factors including:
Improved GPU efficiency through architectural advances and Moore’s Law
Model quantization progress, moving from 16-bit to 4-bit or lower precision
Software optimizations reducing compute and memory bandwidth requirements
Emergence of smaller yet similarly capable models
Better instruction tuning techniques like RLHF and DPO
Competition from open-source models and low-cost providers
This trend raises a critical question: If LLM costs are plummeting so rapidly, why should businesses and developers invest precious time and resources in optimizing their LLM usage? Wouldn’t it make more sense to simply wait for the next wave of cost improvements rather than optimize today? In two words: Jevons Paradox.
The Jevons Paradox was first observed by English economist William Stanley Jevons in 1865. Studying coal consumption during the Industrial Revolution, Jevons made a counterintuitive discovery: as steam engines became more efficient and coal use became more economical, total coal consumption increased rather than decreased driving the (Industrial Revolution) and the total spending up.
This pattern has repeated throughout technological history:
Computing Power: As cost per computation plummeted, we didn’t spend less on computing, instead we found new creative uses for computers, from smartphones to cloud servers
Network Bandwidth: As data transmission got cheaper, we shifted from text messaging to HD video streaming and real-time gaming
Data Storage: As cost per gigabyte fell, we moved from storing documents to hosting entire media libraries and training massive AI models
One could argue that LLMs and Generative AI more broadly are following a similar trajectory. As costs decline, we’re seeing the emergence of new applications:
Embedding AI capabilities into every application and workflow
Real-time analysis of audio transcripts and conversations
Running AI models directly on edge devices and smartphones
Multimodal applications combining text, images, audio and video
In this environment of rapidly falling costs but potential for exponential growth in usage, optimizing LLM costs becomes more, not less, important. Here’s why:
A) Scale Magnifies Everything. When operating at billions of tokens per day, even small inefficiencies have major effects:
A single digit improvement in efficiency can save millions of dollars annually at scale
Every 100 milliseconds of latency is about 8% difference in engagement rates (30% on mobile) [1]
B) Tiered Pricing Persists. While average costs are declining, the market maintains a tiered structure:
Different models offer varying price-performance tradeoffs
ChatGPT Pro at $200 per month breaks the price drop trend perhaps triggering a new wave of premium models
Cost optimization is still required to select the right model for each specific use case
C) Competition Drives Innovation. Companies that master LLM efficiency gain significant advantages:
Ability to offer more competitive pricing
Capacity to handle larger scale operations
Resources to invest in product improvement
D) Performance and Cost Are Linked. Cost optimization often yields performance benefits:
Resource efficiency enables handling larger user loads
More efficiency and reduced latency leads to improved user experience
In this environment, companies that master efficient LLM usage while exploiting new capabilities opened up by falling costs will be best positioned to innovate and scale. This dual focus - efficiency and innovation - will likely characterize successful AI companies in the years ahead.
Motivated by this insight, in the next sections we will dive into the factors that drive LLM cost decay and how to optimize LLM usage in practical applications. The discussion will explore key optimization areas including inference optimization through techniques like Flash Attention and cached prompts, model compression via quantization and distillation, and practical implementation patterns such as response caching, batch processing, and early stopping - all aimed at achieving efficient usage and cost reductions while maintaining model performance and reliability.
9.2. Right-Sizing LLMs: A Strategic Approach¶
Before implementing cost optimization strategies for LLMs, organizations must develop a comprehensive understanding of their own requirements and constraints. This systematic approach prevents both over-engineering and under-provisioning, leading to more efficient and cost-effective implementations.
In this section, we define key performance and cost related metrics that will guide our discussion. Then we propose a set of requirements practitioners should consider before we dive into cost optimization techniques.
9.2.1. Metrics¶
9.2.2. Requirements¶
9.2.2.1. Business Requirements¶
First, one needs to define the problem to be solved and to what extent it is worth to be solved. Use case requirements form the foundation of any LLM implementation project. A clear definition of the specific business problema and task to be accomplished must be established upfront, along with concrete performance metrics covering accuracy, latency and throughput. This should be accompanied by well-defined cost-per-transaction targets, clear ROI expectations, and a strategic allocation of budgets across different use cases to ensure resources are optimally distributed.
Budget and ROI considerations are critical for ensuring the long-term viability of LLM implementations. Organizations must establish clear spending limits that align with their financial capabilities while defining realistic cost-per-transaction targets. ROI expectations need to be carefully established through detailed analysis, followed by a strategic allocation of budgets across various use cases based on their business impact and priority.
Compliance and security requirements cannot be overlooked. This involves a thorough identification of all applicable regulatory requirements and the establishment of robust data handling standards. Organizations must specify comprehensive audit requirements to maintain transparency and accountability, while implementing appropriate security controls to protect sensitive data and system access.
Future-proofing considerations help ensure the longevity and adaptability of LLM implementations. This requires careful planning for scale to accommodate future growth, along with the evaluation of multi-model strategies to reduce dependency on single solutions. Organizations should carefully assess vendor lock-in risks and explore open-source alternatives to maintain flexibility and control over their AI infrastructure.
Chapter Local LLMs in Practice provides a detailed discussion on relevant considerations when Choosing your Model.
9.2.2.2. Performance Requirements¶
Accuracy and quality form the foundation of any LLM deployment’s performance requirements. At its core, this involves determining the minimum level of accuracy that the model must achieve to be considered successful. This serves as a critical baseline for evaluating model performance and making deployment decisions. Establishing clear evaluation metrics, whether through automated measures or human evaluation processes, provides concrete ways to assess if these thresholds are being met. Continuous monitoring of these accuracy metrics ensures the system maintains its performance over time as usage patterns and data distributions evolve. Chapter The Evals Gap provides a detailed discussion on how to evaluate the performance of LLM-based applications.
Latency and throughput requirements are equally crucial for ensuring a positive user experience and system reliability. These specifications define how quickly the system must respond to requests and how many concurrent users it can handle. Response time requirements must be carefully balanced against the computational resources available, while peak load capabilities need to account for usage spikes and growth patterns. The decision between real-time processing for immediate responses versus batch processing for efficiency depends heavily on the use case and user expectations.
9.2.2.3. Operational Requirements¶
Scale and capacity planning forms the foundation of operational requirements for LLM deployments. This involves a comprehensive analysis of expected system usage and growth patterns to ensure the infrastructure can handle both current and future demands. Organizations must carefully project their daily and monthly API call volumes while calculating the average number of tokens per request to accurately estimate resource needs. Understanding usage patterns, including seasonal variations, enables proper capacity planning. Additionally, developing 12-24 month growth projections helps ensure the infrastructure can scale appropriately as demand increases.
Reliability and availability requirements are equally critical for maintaining consistent service quality. These specifications define the expected uptime percentage that the system must maintain, typically expressed as a percentage of total operational time. Organizations need to establish clear maintenance windows that minimize disruption to users while ensuring necessary system updates and optimizations can be performed. Comprehensive backup and failover requirements must be specified to ensure business continuity in case of failures. High availability needs should be clearly defined, including redundancy levels and recovery time objectives, to maintain service quality even during unexpected events.
9.2.2.4. Technical Requirements¶
System integration requirements define how the LLM system will interact and communicate with existing infrastructure and applications. This involves carefully mapping all integration points where the LLM system needs to connect with other systems, establishing standardized data formats and interfaces for seamless communication, implementing robust security measures to protect data in transit, and identifying any technical constraints that could impact integration. Getting these integration requirements right is crucial for ensuring the LLM system can function effectively within the broader technical ecosystem.
Data management requirements address how information will be stored, processed, and maintained within the LLM system. This encompasses determining appropriate storage solutions for maintaining conversation context and history, selecting and configuring vector databases to enable efficient retrieval-augmented generation (RAG), creating comprehensive data retention policies that balance operational needs with resource constraints, and ensuring all data handling practices comply with relevant privacy regulations. Proper data management is essential for both system performance and regulatory compliance, making it a critical consideration in any LLM implementation.
This structured approach to requirements analysis enables organizations to:
Select appropriate models aligned with specific needs
Identify targeted optimization opportunities
Scale efficiently while controlling costs
Develop realistic resource allocation strategies
The following sections explore specific optimization techniques, but their implementation should always be guided by these foundational requirements.
9.3. Quantization¶
Quantization is a common and relevant technique in making LLMs more efficient and accessible. At a high level, quantization reduces the number of bits used to represent a model’s parameters. The most common form of quantization is to represent model’s weights at lower precision at post-training phase. It has become a standard technique to generate a series of quantized models given a large pre-trained base model.
While a standard pre-trained LLM might use 32-bit floating-point (FP32) or 16-bit floating-point (FP16) numbers to store its weights, quantized versions can operate at lower precision levels such as 8, 4 or even 2 bits per parameter, reducing memory footprint without proportional losses in performance, necessarily. For instance, for a model of 30 billion parameters, using FP32 means 4 bytes per weight or 120 GB for the whole weights. If the model is quantized such that weights are represented in 1 byte, the memory needed for the model’s weights decreases to 30 GB, hence potentially fitting into consumer grade hardware. This is done at the cost of precision loss, but the trade-off is often worth it though require careful analysis.
Let’s take a look at model weights of a language model (SmolLM2-135M-Instruct) that has been quantized to 2-bit and 16-bit precisions. We will use an utility function load_gguf from the taming_utils package to load model weights of the quantized models directly from Hugging Face.
from taming_utils import load_gguf
MODEL_NAME = "bartowski/SmolLM2-135M-Instruct-GGUF"
GGUF_FILE_Q2_K = "SmolLM2-135M-Instruct-Q2_K.gguf"
GGUF_FILE_F16 = "SmolLM2-135M-Instruct-F16.gguf"
model_q2_k = load_gguf(model_name=MODEL_NAME,
gguf_file=GGUF_FILE_Q2_K)
model_f16 = load_gguf(model_name=MODEL_NAME,
gguf_file=GGUF_FILE_F16)
We extract the MLP weights from the first layer of the model as a proxy.
mlp_weights_q2_k = model_q2_k.model.layers[0].mlp.gate_proj.weight
mlp_weights_f16 = model_f16.model.layers[0].mlp.gate_proj.weight
Original weights at 16-bit precision:
mlp_weights_f16
Parameter containing:
tensor([[-0.0145, 0.1826, 0.1377, ..., 0.1719, -0.1387, -0.0298],
[-0.1631, 0.0781, -0.2051, ..., -0.2070, -0.0334, 0.2891],
[-0.1768, -0.0488, -0.2393, ..., -0.0396, -0.1348, -0.1533],
...,
[ 0.0771, 0.0845, -0.0232, ..., 0.0178, -0.1040, -0.0771],
[ 0.1582, 0.1167, -0.0474, ..., 0.0845, 0.0359, -0.2500],
[ 0.0432, 0.0972, 0.0933, ..., 0.2188, 0.0776, 0.0674]],
requires_grad=True)
Quantized weights at 2-bit precision:
mlp_weights_q2_k
Parameter containing:
tensor([[-0.0028, 0.1852, 0.1396, ..., 0.1506, -0.1635, -0.0043],
[-0.1768, 0.0680, -0.2257, ..., -0.1890, -0.0464, 0.2960],
[-0.1840, -0.0451, -0.2395, ..., -0.0413, -0.1446, -0.1446],
...,
[ 0.0621, 0.0621, -0.0478, ..., 0.0038, -0.0830, -0.0830],
[ 0.1473, 0.0926, -0.0547, ..., 0.0824, 0.0429, -0.2737],
[ 0.0355, 0.0782, 0.0782, ..., 0.2043, 0.0740, 0.0740]],
requires_grad=True)
How do they compare? We arrive at a Pearson correlation of 99.7% between the two sets of weights.
import numpy as np
# Convert tensors to numpy arrays (detach from computation graph if needed)
weights_f16 = mlp_weights_f16.detach().cpu().numpy()
weights_q2_k = mlp_weights_q2_k.detach().cpu().numpy()
flat_f16 = weights_f16.flatten()
flat_q2_k = weights_q2_k.flatten()
# Calculate correlation
correlation = np.corrcoef(flat_f16, flat_q2_k)[0,1]
print(f"Pearson correlation: {correlation:.4f}")
Pearson correlation: 0.9970
Quantization[2] is a powerful technique for reducing the memory footprint of LLMs. This can be exemplified by the case of LLaMa 3.3 70B as quantized by [Unsloth, 2024] [3]. The model’s memory requirements vary significantly based on the quantization level used as demonstrated in Fig. 9.2.
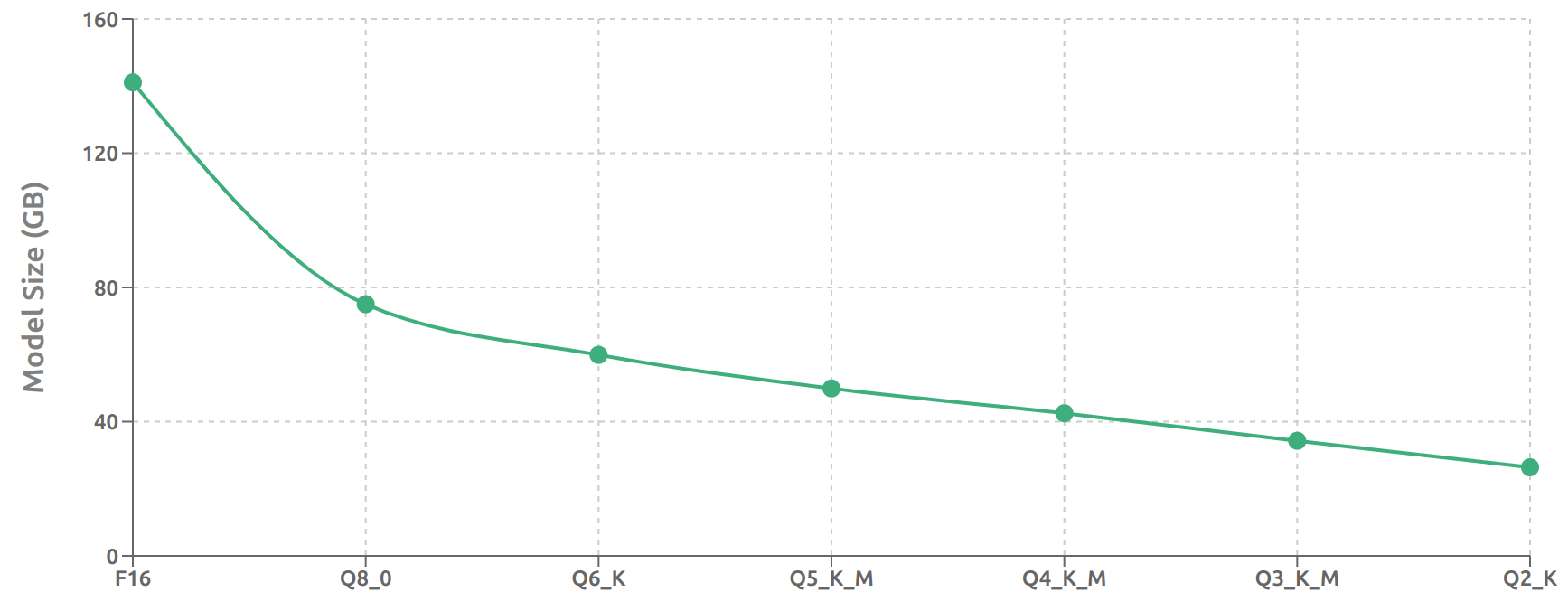
Fig. 9.2 Quantized Model Size: unsloth/Llama-3.3-70B-Instruct-GGUF¶
We observe that the quantization process yields remarkable reductions in model size, demonstrating a clear trade-off between precision and memory requirements. The transition from F16 (141.1 GB) to Q8_0 (75 GB) achieves a dramatic 47% reduction in model size while maintaining relatively high numerical precision. Further quantization levels reveal an interesting pattern of diminishing returns - each step down in precision yields progressively smaller absolute size reductions, though the cumulative effect remains significant. At the extreme end, the Q2_K model (26.4 GB) requires only 19% of the storage space of its F16 counterpart [4].
This wide spectrum of model sizes enables deployment across diverse hardware environments. The lightweight Q2_K variant opens possibilities for running inference on consumer-grade hardware like high-end laptops or desktop computers. In contrast, the full-precision F16 model demands enterprise-grade computing resources with substantial memory capacity. This flexibility in deployment options makes quantization a powerful tool for democratizing access to large language models while managing computational costs.
While quantization has proven highly effective, there is a limit to how far it can be pushed - specifically, the 1-bit ceiling. A notable advancement in this space is BitNet [Wang et al., 2024] which pushes the boundaries of extreme quantization.
BitNet’s implementation, bitnet.cpp, has demonstrated significant performance improvements across both ARM and x86 architectures (see Fig. 9.3). When compared to llama.cpp, the framework achieves speedups ranging from 1.37x to 5.07x on ARM processors and 2.37x to 6.17x on x86 systems. These performance gains scale with model size - larger models benefit more substantially from BitNet’s optimizations. The efficiency improvements extend beyond raw speed: energy consumption drops by 55-70% on ARM and 71-82% on x86 processors. Perhaps most impressively, bitnet.cpp enables running a 100B parameter BitNet b1.58 model on a single CPU at speeds matching human reading pace (5-7 tokens per second).
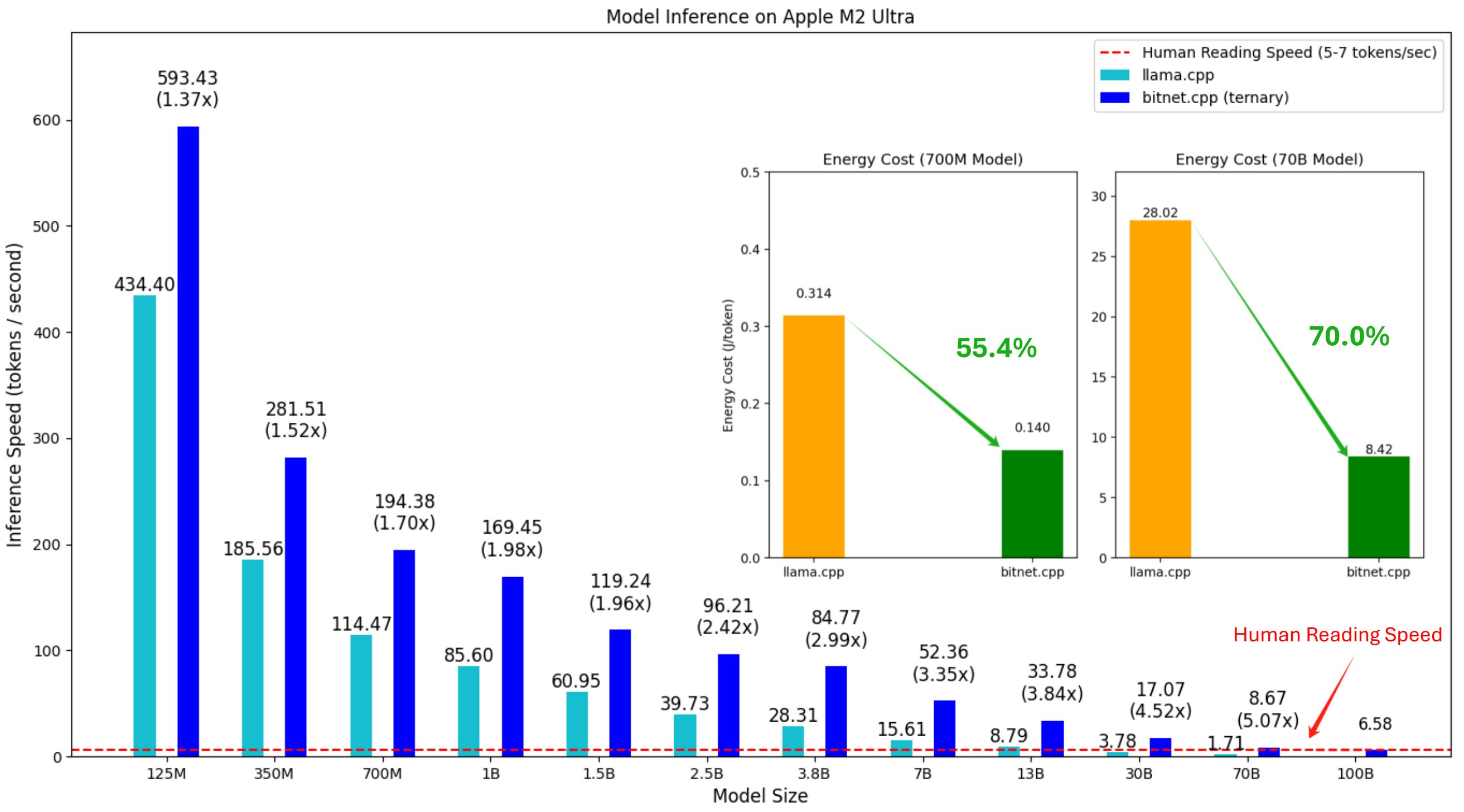
Fig. 9.3 BitNet: [Wang et al., 2024]¶
The framework’s initial release focused on CPU inference optimization, with particular emphasis on 1-bit LLM architectures (BitNet b1.58). While initial testing shows promising results, these findings are specific to the tested models and kernels (its specialized kernels are carefully crafted to exploit the unique characteristics of these extremely quantized models). Further validation is needed before generalizing these results across different architectures and use cases.
As a relatively recent innovation, 1-bit LLMs represent an exciting frontier in model compression. However, their full potential and limitations require additional research and real-world validation. The technology demonstrates how creative approaches to quantization can continue pushing the boundaries of efficient AI deployment.
Beyond its memory footprint reduction, quantization delivers several compelling advantages: it accelerates computation through faster arithmetic operations and larger batch sizes, reduces costs by enabling deployment on less expensive hardware and making LLMs more accessible to smaller organizations, and improves energy efficiency by lowering memory bandwidth usage and power consumption - particularly beneficial for mobile and edge devices, ultimately contributing to more sustainable AI deployment.
Each reduction in precision risks performance degradation. Finding optimal quantization schemes remains an active research area. See Case Study on Quantization for Local Models in Chapter Local LLMs in Practice for more details.
9.4. Check-list¶
Planning and Requirements
Start with a clear understanding of your application’s needs and the factors that contribute to LLM costs
Choose the right model for your task, balancing performance and cost
Be aware of the potential challenges and limitations of open-source LLMs and take appropriate measures to mitigate them
Model Optimization
Explore model compression and quantization to reduce model size and computational demands
Fine-tune pre-trained models on domain-specific data to improve accuracy and efficiency
Consider using RAG to enhance performance and reduce reliance on purely generative processes
Prompt Engineering
Optimize prompts and utilize prompt engineering techniques to minimize token usage
Experiment with different prompting strategies to unlock the full potential of open-source LLMs
Infrastructure and Operations
Implement caching and batching strategies to optimize resource utilization
Monitor LLM usage patterns and costs to identify areas for optimization
Set up observability and logging to track model performance and costs
Establish automated testing and evaluation pipelines
Cost Management
Track and analyze inference costs across different model variants
Implement cost allocation and chargeback mechanisms
Set up cost alerts and budgeting controls
Regularly review and optimize resource utilization
9.5. Conclusion¶

@misc{tharsistpsouza2024tamingllms,
author = {Tharsis T. P. Souza},
title = {Taming LLMs: A Practical Guide to LLM Pitfalls with Open Source Software},
year = {2024},
chapter = {The Falling Cost Paradox},
journal = {GitHub repository},
url = {https://github.com/souzatharsis/tamingLLMs)
}
9.6. References¶
Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming Ma, Hongyu Wang, Yan Xia, and Furu Wei. 1-bit ai infra: part 1.1, fast and lossless bitnet b1.58 inference on cpus. 2024. URL: https://arxiv.org/abs/2410.16144, arXiv:2410.16144.
Andreessen Horowitz. Llmflation: understanding and mitigating llm inference cost. Blog Post, 2024. Analysis of LLM inference costs and strategies for optimization. URL: https://a16z.com/llmflation-llm-inference-cost/.
HuggingFace. Gguf quantization types. Online Documentation, 2024w. Documentation on different quantization types available for GGUF models. URL: https://huggingface.co/docs/hub/gguf#quantization-types.
Unsloth. Llama-3.3-70b-instruct-gguf. HuggingFace Model, 2024. GGUF quantized version of Meta's Llama 3.3 70B instruction-tuned model. URL: https://huggingface.co/unsloth/Llama-3.3-70B-Instruct-GGUF.